안녕하세요
27년차 진로탐색꾼 조녁입니다!
오늘은 텐서플로우 자격증 과정 세번째 강좌인
' Natural Language Processing in TensorFlow '
4주차 강의(Sequence models and literature) 및 자료를 공부했습니다.
첫번째 영상, A conversation with Andrew Ng
시퀀스 모델에서 흥미로웠던 것은 , 뒤에 올 단어를 예측하여 생성해본 것입니다. 이번에는 셰익스피어의 문학을 인식하고 그것을 통해 예측해 볼 것입니다.
두번째 영상, Introduction
우리는 앞에 문장에 따라올 새로운 텍스트를 생성해봤다. 앞서 이미지 분류 문제에서도, 사진속 픽셀들을 학습해서 패션MNIST나 글씨MNIST를 분류할 수 있었다. 이와 마찬가지로 우리는 많은 문장들 속 단어를 학습시키면, 테스트셋 문장의 다음에 올 단어를 예측할 수 있다.
예를 들어, "반짝 반짝 작은" 이라는 텍스트 뒤에는 "별" 이 올 것이다. 이것은 꽤나 정교한 텍스트 생성이 될 것이다.
세번째 영상, Looking into the code
전통 아일랜드 노래를 하나의 string으로 길게 가져왔다. 여기서 줄 간격은 '\n'으로 나눴다.
그러고 난 후 모든 알파벳을 소문자로 하고, 문장별로 나눠서 corpus에 할당한다.
토크나이저를 사용해서 corpus안에 있는 단어들을 딕셔너리로 만들어 준다.
총 단어의 갯수는 워드 인덱스의 길이에 외부단어를 고려하는(OOV)를 하나 더해서 구할 수 있다.

네번째 영상, Training the data
우선 input_sequences 라는 x 데이터를 생성한다. (파이썬의 리스트 형식)
그 다음 corpus의 line을 tokenizer.texts_to_sequences 메서드를 사용하면 아래 그림3과 같이 시퀀스 형태로 토크나이징 된다.


다음으로 , 반복하여 n_gram_sequence를 생성해줍니다. 그 다음에 input_sequences에 append해주면 그림4 와 같은 결과가 나옵니다.

다음으로 corpus(말뭉치) 내에서 가장 긴 시퀀스를 아래 코드로 찾아줍니다.

그 다음으로는 모든 시퀀스의 길이가 같도록 패딩을 해줍니다. 그림6의 실행 결과는 그림7과 같습니다.


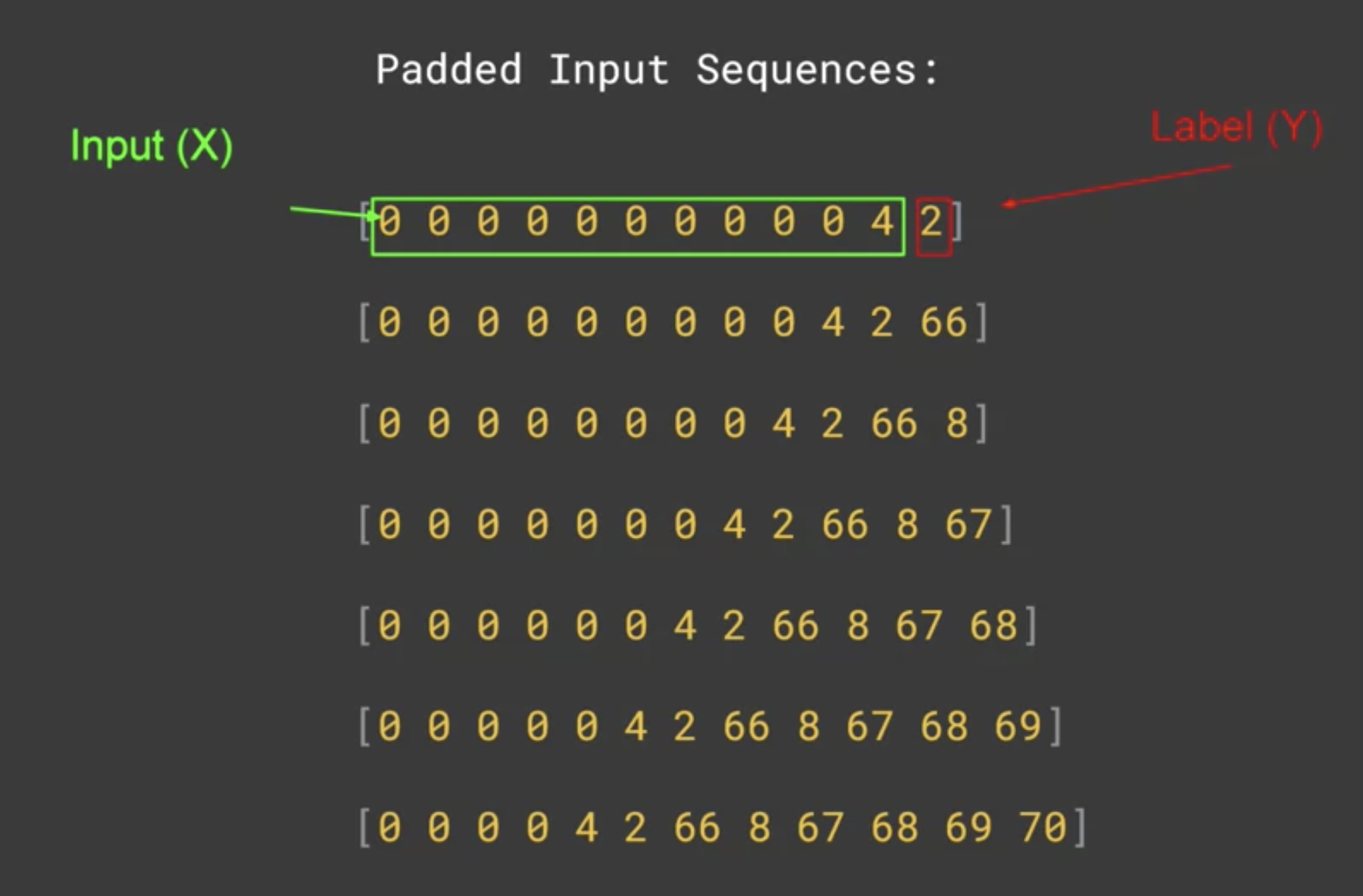
이제 데이터를 얻었으니 X와 Y로 나눠준다. 아래 그림8과 같이 각 시퀀스의 맨 마지막 값을 Label(Y)로 삼고 그 외에 모든 값을 Input(X)로 한다. 우리는 패딩을 해서 길이를 맞춰줬기 때문에, 그저 마지막에 오는 토큰 값을 레이블로 삼기만 하면 된다.
다섯번째 영상, More on training the data
그림9 코드와 같이 x, label로 input_sequences를 나눠준다.

그리고 분류 문제이므로 y값을 원핫 인코딩 해줍니다. keras.utils.to_categorical 메서드를 써서, label 리스트와 클래스 갯수를 지정해서 사용할 수 있다. 그림10 코드로 원핫인코딩해주면 결과는 그림11과 같다.


이제, 신경망에 학습시킬 수 있는 자료의 전처리가 완료되었습니다.
여섯번째 읽기자료,
Course 3 - Week 4 - Lesson 1 - Notebook : gist.github.com/jonhyuk0922/3d2ec5875902a3fd3bf4dbb040edefd7
Course 3 - Week 4 - Lesson 1 - Notebook.ipynb의 사본
Course 3 - Week 4 - Lesson 1 - Notebook.ipynb의 사본. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
일곱번째 영상, Notebook for Lesson1
위에 깃허브로 주어진 코드를 같이 리뷰했다. 앞서 배운 전처리를 진행했고, 주어진 예시 문장 뒤에 100단어를 예측해봤다.
feeding해준 단어가 200개 남짓밖에 안되기때문에(턱없이 부족) 500에폭을 돌렸고, 실제로 예측에서는 문장이 뒤로 갈 수록 문장같지 않은 것들이 왔다.
여덟번째 영상, FInding what the next word should be
위에서 전처리한 데이터를 feeding 해줄 신경망을 구축합니다.
첫줄에서 임베딩 레이어를 구축하는데 , [모든 단어를 피딩/64차원/입력 길이는 가장긴 시퀀스 -1(레이블)] 로 파라미터를 정한다.
둘째줄에서 LSTM은 20 단위를 지정하지만, 다른 걸로 바꿔서 해봐도 좋다.
세번째 줄에는 softmax 활성화함수를 사용한 덴스 레이어를 생성한다. 여기서 레이블을 원핫 인코딩했으므로, 늘어선 0 중에 index번째의 1이 켜진다고 이해할 수 있다.
다음으로 모델을 컴파일해주고, 학습은 데이터가 적으므로 500에폭 돌려준다.
결과는 그림13 과 같다. 200에폭 즈음에 한번 가라앉는데 아마 오버피팅이 발생했을 것이다. 후에 학습시킬때 이런점을 유의하자.


아홉번째 영상, Example
위에 학습시킨 신경망을 통해 아래와 같은 문장을 예측해봤습니다. 예측해본 문장에는 반복이 많이 나타나는 것을 볼 수 있다.

그래서 양방향 LSTM으로 변경해서 다시 학습시켰고, 그림13보다는 좀더 빠르게 수렴하는 것을 확인할 수 있습니다.
그 결과, 반복은 발생하고 있지만 의미는 아까보다는 더 이해하기 쉬운 문장을 출력했습니다.

열번째 영상, Predicting a word
예측을 위해 우선 seed text를 토크나이징 하고(text_to_sequences 메서드 사용)
패딩도 해준다. 이제는 그림16 코드로 예측을 진행하는데, 이를 통해 등장할 가능성이 가장 높은 단어의 토큰을 얻을 수 있다.

총 10번 예측하는 코드는 아래와 같다. 이렇게 실행했을 때, 뒤로 갈수록 정확도가 떨어지는 걸 확인할 수 있다. 왜냐하면, 단어 하나하나를 예측하기때문에 뒤로갈수록 덜 확실해 진다. 그림18 의 횡설수설하는 결과를 확인하자.


더 정확한 예측을 위해선 학습데이터가 큰것을 사용해야한다. 다음 강의에서는 모델의 조정을 통해 효율을 올려볼 것이다.
열한번째 영상, Poetry!
우리는 이전 강의에서 한가지 노래를 가지고 뒤에 올 단어를 예측해보고자 했지만, 뒤로 갈수록 빠르게 횡설수설(gibberish)하는 것을 확인했다.
신경망에 어떤 영향을 주는 지 보기위해 1,692개의 문장이 포함된 노래가사들을 준비했다. (다음 읽기자료 참고)
열두번째 읽기자료, link to Laurence's poetry
storage.googleapis.com/laurencemoroney-blog.appspot.com/irish-lyrics-eof.txt
열세번째 영상, Looking into the code
코드를 함께 살펴보자. 더큰 데이터를 받아들이기 위해 몇가지 하이퍼 파라미터의 변경만을 주고 있다. 자유롭게 바꾸면서 실험해봐라.
세가지를 변경할 건데, 첫번째로 임베딩 차원을 100으로 늘려줬다. 그리고 LSTM의 유닛수를 150으로 늘렸다.
마지막으로 가장 큰 영향을 미치는 옵티마이저의 학습속도를 정해줬다. 파라미터를 변경하면서 어떻게 다른 시들이 나오는 지 살펴보라.

열네번째 영상, Laurence the poet!
짜여진 코드를 실행하면, 100에폭 학습을 하는데 약 7분 소요될것이다.
이를 바탕으로 100단어를 예측해보면 마치 한편의 시와 같다.
(나는 학습에 유명한 영화 대사들을 사용했다.)
열다섯번째 읽기자료, Check out the code!
gist.github.com/jonhyuk0922/7b55d08ae374d9bf57d7f7030a2fb481
Course 3 - Week 4 - Lesson 2 - Notebook.ipynb의 사본
Course 3 - Week 4 - Lesson 2 - Notebook.ipynb의 사본. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
열여섯번째 영상, Your next task
위와 같은 접근방식은 매우 큰 본문을 가지고 있을 때 잘 작동한다. 그러나 우리의 과제인 셰익스피어 본문은 크기가 너무 커서 내 컴퓨터로는 감당이 쉽지않다. 우리는 아래 링크에서 배울 수 있는 character-based RNN을 통해 문제를 해결해볼 것이다.
과제하러 갑시다.
* 여기서 word 와 character 차이점 정리하자면, character는 뜻을 포함한 상형문자로 word에 비해 더 많은 메모리를 가진다.
열일곱번째 읽기자료, Link to generating text using a character-based RNN
www.tensorflow.org/tutorials/text/text_generation#%EC%84%A4%EC%A0%95
순환 신경망을 활용한 문자열 생성 | TensorFlow Core
Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용을 반영하기 위해 노력함에도 불구하고 공식 영문 문서의 내용과 일치하지 않을 수
www.tensorflow.org
퀴즈에서 배운점
-토크나이저를 사용해 문장의 list를 만들때 fit_on_texts(sentences)를 사용한다.
-시를 생성할 때, 뒤로갈수록 횡설수설하는 이유는 더 많은 단어를 생성할수록 단어가 매칭될 확률이 낮아지기 때문이다.
-LSTM을 사용하면, 의미가 연관된 단어가 연속되어 있지 않더라도 앞에있는 단어의 뜻을 cell state로 뒤에 전달해준다.
과제 : 셰익스피어 Sonnet corpus를 학습시켜서 시를 만드시오!
코스3 마무리 , 지난 4주간(나도 실제로 1주일걸림..) 텐서플로우를 이용한 자연어 처리에 대해 배웠다.
내용 정리 : 우선 신경망에 먹일 수 있도록 텍스트를 토큰화하고 패딩하는 첫번째 원칙이 있었다.
그런 다음 임베딩을 통해 단어를 벡터에 매핑하는 방법과 비슷한 의미를 가진 단어가 비슷한 방향을 가리킴을 배웠다.
여기서 시퀀스 모델이 등장했는데, 이를 통해 단어를 분리해 개개인만 다루는 것이 아니라 그 단어들이 다른 단어들과 있을 때 어떻게 상호작용하는 지 살펴봤다. 이를 통해 단어의 감정을 이해하는데 더 나아갈 수 있었다.
우리는 이 배운 것들을 이용하여 최종적으로 시 생성기를 만들어볼 수 있었다.
이것은 시작일 뿐이지만 좋은 시작이었길 바란다. (NLP 빡셌다.. 자주 복습하며 더 채워가자!)

'머신러닝 & 딥러닝 공부 > Tensorflow' 카테고리의 다른 글
| [Tensorflow dev 자격증] Deep Neural Networks for Time Series (0) | 2021.03.02 |
|---|---|
| [Tensorflow dev 자격증] Sequences and Prediction (2) | 2021.03.01 |
| [Tensorflow dev 자격증] Sequence models (0) | 2021.02.24 |
| [Tensorflow dev 자격증] Word Embeddings (0) | 2021.02.17 |
| [NLP 오류해결] Stopword(불용어) Tensorflow 2.0 에서 사용 시 import 오류 해결 방법 (0) | 2021.02.15 |



