안녕하세요
27년차 진로탐색꾼 조녁입니다!
오늘은 텐서플로우 자격증 과정 세번째 강좌인
' Natural Language Processing in TensorFlow '
3주차 강의(Sequence models) 및 자료를 공부했습니다.
지난 주차가 내용이
많아서 좀 힘들었는데 이번주는 지난주에 비해 적다.. 다행이다.
첫번째 영상, 텐서플로우에서 sequence model 구축하는 방법 배운다. 왜냐하면 텍스트에서 순서는 중요하기 때문이다. 예를들어 "개가 모자를 썼다." 라는 문장을 "모자가 개를 썼다." 로 바꾸면 의미없는 우스꽝 스러운 문장이 되어 버린다.
이에 대해 RNN , GIO,LSTM 과 같은 것들을 배울 것이다.
두번째 영상, Introduction
아래 그림1 과 같이 통상적으로는 예제와 답을 넣고 규칙을 도출해내는게 머신러닝의 원리이다.
이 때, 이 과정이 반복되는 것이 RNN에 기초가 되지만 우리는 RNN 의 작동원리에 대해서 공부하진 않을 것이다.

세번째 읽기자료, sequence modeling course , 7일간 무료로 들을 수 있는 앤드류의 강의다. RNN 의 원리를 다룬다.
www.coursera.org/lecture/nlp-sequence-models/deep-rnns-ehs0S
Deep RNNs - Recurrent Neural Networks | Coursera
Video created by deeplearning.ai for the course "Sequence Models". Learn about recurrent neural networks. This type of model has been proven to perform extremely well on temporal data. It has several variants including LSTMs, GRUs and ...
www.coursera.org
네번째 영상, LSTMs
아래와 같이 우리는 blue 를 통해 힌트를 얻어 sky를 유추할 수 있습니다.

그리고 단어와 단어 사이가 멀더라도 유추할 수 있습니다. 아래 예시와 사진을 보십시오.


또한 Cell State를 통해 양방향 유추가 가능합니다. 이것은 RNN을 업그레이드 한 LSTMs 인데 이후 모델을 살펴볼 때, 양방향이 의미하는 바를 더 자세히 볼 수 있습니다.
다섯번째 읽기자료, LSTMs에 대해 더 공부하고 싶다면 아래 링크로 들어가세요.
www.coursera.org/lecture/nlp-sequence-models/long-short-term-memory-lstm-KXoay
Long Short Term Memory (LSTM) - Recurrent Neural Networks | Coursera
Video created by deeplearning.ai for the course "Sequence Models". Learn about recurrent neural networks. This type of model has been proven to perform extremely well on temporal data. It has several variants including LSTMs, GRUs and ...
www.coursera.org
여섯번째 영상,
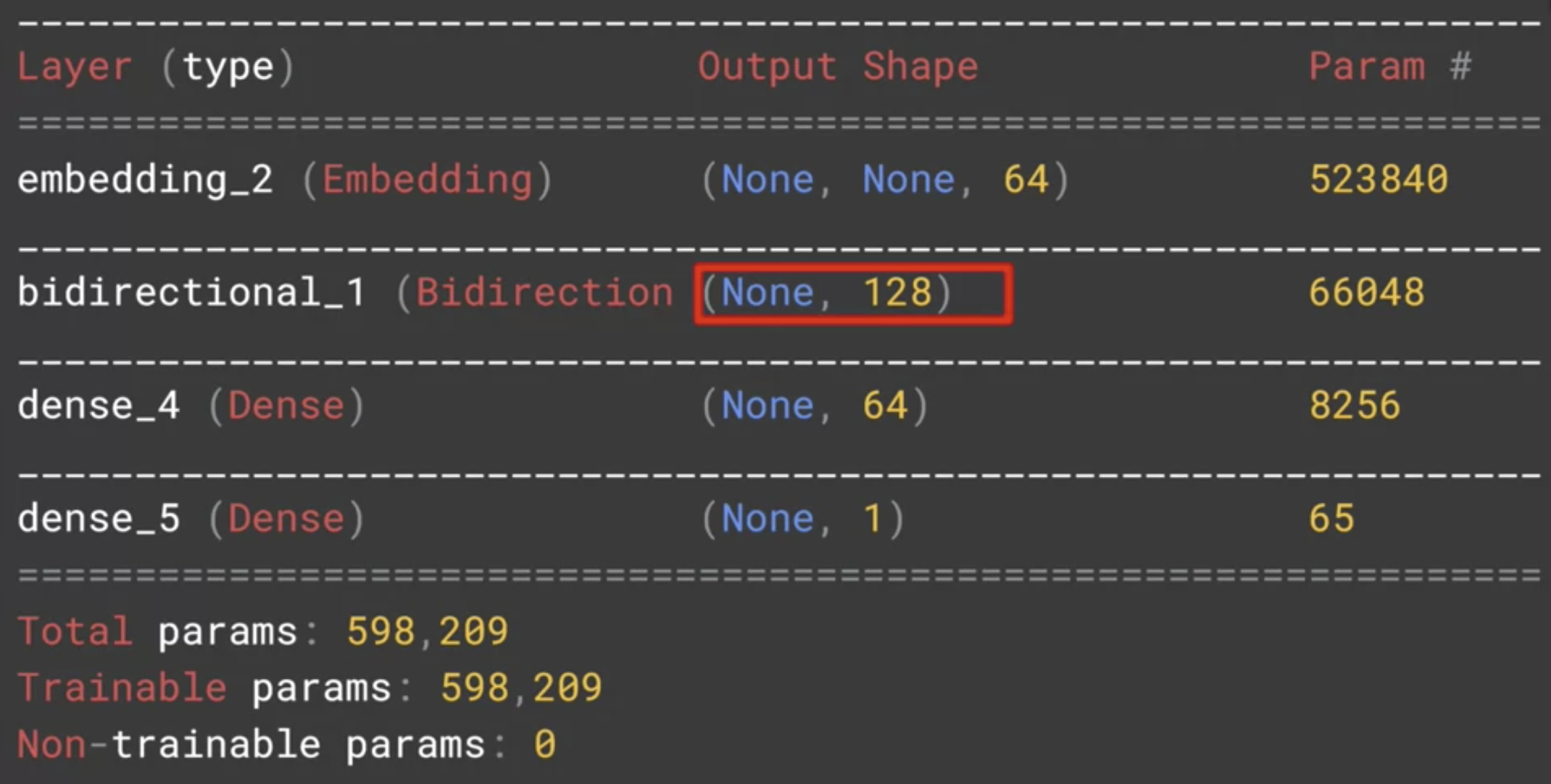
아래 코드에서 2번째층에 LSTMs 코드가 추가되었습니다. 파라미터값(64)은 원하는 출력값을 입력합니다.
여기서 LSTM 코드를 tf.keras.layers.Bidirectional() 로 감싸주는 건 양방향으로 만드는 것입니다.

모델 요약을 살펴보면 아래와 같다. 특별히 LSTMs의 출력을 64로 원했지만, 양방향으로 작용해서 128이 출력된 것을 볼 수 있다.
LSTMs 층을 두개로 쌓을 때는 첫번째 LSTMs 층에 return_sequences=True 파라미터를 넣어줘야한다.
이것은 LSTMs 의 출력을 다른 층에 먹이기 위해서 필요한 파라미터입니다.

일곱번째 읽기자료, 1개 층 LSTMs 와 2개층 LSTMs를 코드로 확인하십시오.
1개층 LSTMs : gist.github.com/jonhyuk0922/b04877033c3faac40d6858896665e213
Course 3 - Week 3 - LSTMs 층 1개
Course 3 - Week 3 - LSTMs 층 1개. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
2개층 LSTMs : gist.github.com/jonhyuk0922/91990843211cc790a490f2d6ca50c17c
Course 3 - Week 3 - LSTMs 층 2개
Course 3 - Week 3 - LSTMs 층 2개. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
여덟번째 영상,
아래 그림을 보면 1개층인 것과 2개층인 것 중에서 2개층인 것이 더 매끄러운 것을 확인할 수 있다. (매끄러울 수록 신뢰도 상승)

아홉번째 영상, 이제 컨볼루션이 포함된 RNN 인 Gated Recurrent Units(GRUs)를 배울 것이다.
열번째 영상, LSTM 없을 때와 LSTM을 사용했을 떄를 비교해보면, 정확도는 아래와 같이 LSTM을 사용했을 때 빠르고 꾸준하게 상승하는 것을 볼 수 있다. 그러나 검증 정확도는 LSTM을 사용했을 때 꾸준히 떨어진다. (하지만 가장 작은 값이 LSTM을 사용했을 때와 비슷함)
따라서, LSTM을 약간 조정하면 문제 해결에 도움이 될 것입니다.

열한번째 영상, Using a convolutional network
임베딩한 이후 컨볼루션을 추가하면 아래와 같다. 아래 모델에 대한 효율은, 정확도는 증가하지만 에폭이 늘수록 검증 정확도에서 과대적합으로 다가가고 있음을 볼 수 있다.


열두번째 읽기자료, CNN 모델 코드
gist.github.com/jonhyuk0922/c52fe74ff6aeb175ca7d8907e629cdc5
Course 3 - Week 3 - CNN
Course 3 - Week 3 - CNN. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
열세번째 영상, Going back to the IMDB dataset
IMDB 데이터셋에 대한 모델별 효율
*오버피팅 최하가 가장 오버피팅이 심한 것_ 손실 그래프 매끈할수록 좋게 평가
| 모델 \ 효율 | 파라미터수 | 정확도/유효성 검증 | 에폭 당 소요시간 | 오버피팅 정도 |
| DNN | 171,533 | 1.00/0.85~0.8 | 5s | 중 |
| RNN(LSTM) | 30,129 | 1.00/0.85~0.82 | 43s | 하 |
| RNN(GRU) | 169,997 | 1.00/0.85~0.8 | 20s | 상 |
| CNN | 171,149 | 1.00/0.85~0.825 | 6s | 최하 |
열네번째 읽기자료, GRU 모델 코드
gist.github.com/jonhyuk0922/1a4b1bdcf3aff1abefcf875a339e17e0
Course 3 - Week 3 - GRU(and optional LSTM and Conv1D)
Course 3 - Week 3 - GRU(and optional LSTM and Conv1D) - course-3-week-3-gru-and-optional-lstm-and-conv1d.ipynb
gist.github.com
열다섯번째 영상, 유형별로 비교해보시오(위의 표 참고). 이미지보다 텍스트가 오버피팅이 많이 일어난다. 왜냐하면 유효성 검증 데이터에 있는 단어들 중에 학습되지 않은 것들이 많기 때문이다. 우리는 이런 문제를 어떻게 해결 할 수 있을까? (다음 강의에서 알려주겠지? ..)
열여섯번째 읽기자료,
Sarcasm with Bidirectional LSTM : gist.github.com/jonhyuk0922/89d4661e862f34b65cd2be1f07e08a4f
Course 3 - Week 3 - Sarcasm with Bidirectional LSTM
Course 3 - Week 3 - Sarcasm with Bidirectional LSTM - course-3-week-3-sarcasm-with-bidirectional-lstm.ipynb
gist.github.com
Sarcasm with 1D Convolutional Layer : gist.github.com/jonhyuk0922/29d4f4c1874d26e0cf4eb27b985b3b33
Course 3 - Week 3 - Sarcasm with 1D Convolutional Layer
Course 3 - Week 3 - Sarcasm with 1D Convolutional Layer - course-3-week-3-sarcasm-with-1d-convolutional-layer.ipynb
gist.github.com
퀴즈,
무난했다.
열여덟번째 읽기자료, 3주차 마무리(Wrap up)
이제 학습한 도구들을 사용하여 텍스트를 예측하는 방법을 배울 것이다. 이는 궁극적으로 텍스트를 만들 수 있음을 의미한다.
단어 시퀀스를 학습시키면 시퀀스에서 다음으로 오는 가장 일반적인 단어를 예측할 수 있다.
그러므로 새로운 단어 시퀀스에서 시작할때 단어를 기반으로하는 모델을 만들 수 있다.
eg) 아일랜드 노래, 셰익스피어 시에서 임베딩을 사용하여 새로운 단어 세트를 만들 것이다.
과제 : Sentiment140 dataset with 1.6 million tweets
www.kaggle.com/kazanova/sentiment140
Sentiment140 dataset with 1.6 million tweets
Sentiment analysis with tweets
www.kaggle.com
'머신러닝 & 딥러닝 공부 > Tensorflow' 카테고리의 다른 글
| [Tensorflow dev 자격증] Sequences and Prediction (2) | 2021.03.01 |
|---|---|
| [Tensorflow dev 자격증] Sequence models and literature (0) | 2021.02.25 |
| [Tensorflow dev 자격증] Word Embeddings (0) | 2021.02.17 |
| [NLP 오류해결] Stopword(불용어) Tensorflow 2.0 에서 사용 시 import 오류 해결 방법 (0) | 2021.02.15 |
| [Tensorflow dev 자격증] Sentiment in text (0) | 2021.02.15 |



