안녕하세요
27년차 진로탐색꾼 조녁입니다!
오늘은 텐서플로우 자격증 과정 세번째 강좌인
' Natural Language Processing in TensorFlow '
2주차 강의(Word Embeddings) 및 자료를 공부했습니다.
확실히 1주차 들어보니, 처음 듣는 개념들이 많다보니 뇌가 말랑말랑 받아들이기까지 시간이 좀 걸릴 것 같아요!.. ㅠ
첫번째 영상, 이번주는 임베딩에 대해 배울 것이다.
두번째 영상, 우리는 이미지에서 특징을 추출하는 것과 거의 같은 방식으로 단어 모음에서 감정을 추출할 것이다. 이 과정이 임베딩이다.
이번주에는 임베딩을 사용하는 방법과 해당 시각화를 제공하는 분류기를 빌드하는 방법을 배웁니다. 예시로 영화 리뷰가 긍정적인 지, 부정적인 지 분류하는 임베딩을 배울 것입니다. 우선 아래 그림과 같이 영화 리뷰 분류를 시각화한 IMDB 분류를 작성하는 방법을 배우겠습니다.

세번째 영상, 우리는 Tensorflow에 내장된 data set을 사용할 것이다. IMDB 에는 5만개의 리뷰 데이터가 들어있다.

네번째 읽기자료, IMDB 데이터랑 관련 교수님 페이지, 논문이 들어있다. ai.stanford.edu/~amaas/data/sentiment/
Sentiment Analysis
Publications Using the Dataset Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. (2011). Learning Word Vectors for Sentiment Analysis. The 49th Annual Meeting of the Association for Computational Linguistics (A
ai.stanford.edu
다섯번째 영상, 코드를 살펴보겠습니다. 우선 이 모든 코드는 python3 에서 작성되었습니다.
import tensorflow as tf
print(tf.__version__)
우선 텐서플로우 2.x 버전 확인해줍니다.
import tensorflow_datasets as tfds
imdb, info = tfds.load("imdb_reviews", with_info=True, as_supervised=True)
그다음으로 데이터를 로드해줍니다.
import numpy as np
train_data, test_data = imdb['train'], imdb['test']
학습데이터와 검증데이터 각각 25,000개씩 다운로드됩니다.
training_sentences = []
training_labels = []
testing_sentences = []
testing_labels = []
# str(s.tonumpy()) is needed in Python3 instead of just s.numpy()
for s,l in train_data:
training_sentences.append(s.numpy().decode('utf8'))
training_labels.append(l.numpy())
for s,l in test_data:
testing_sentences.append(s.numpy().decode('utf8'))
testing_labels.append(l.numpy())
training_labels_final = np.array(training_labels)
testing_labels_final = np.array(testing_labels)
다음엔 학습과 검증 데이터를 sentences , labels로 list를 생성합니다.
그다음 for문으로 데이터를 입력한다. s,l은 텐서이므로 numpy를 사용한다.
학습할때 레이블은 넘파이값이므로 아래 두줄로 넘파이 배열로 만들어준다.
vocab_size = 10000
embedding_dim = 16
max_length = 120
trunc_type='post'
oov_tok = "<OOV>"
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(training_sentences)
padded = pad_sequences(sequences,maxlen=max_length, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences,maxlen=max_length)
다음으로 문장을 토큰화합니다. 변경 및 편집을 용이하게 하기 위해 하이퍼 파라미터를 맨 위에 배치했다.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
다음으로 모델을 정의해줍니다. 두번째 줄을 제외하곤 익숙할 것입니다. 두번째줄이 텍스트 감정 분류에 핵심이 되는 임베딩입니다.
여섯번째 영상, 입베딩 작동 방식은 이 단원을 벗어나므로 쉽게 생각할 것입니다. 비슷한 의미를 가진 단어들은 보통 붙어서 옵니다. 우리가 긍정적이라고 분류한 리뷰에서 기쁘고 행복하다고 나오면 두개는 같이 나오기때문에 그들은 비슷한 벡터를 가질 것입니다.
위에 모델 코드에서 Flatten() 레이어를 아래와 같이 고쳐주었을 때 어떤 차이가 발생하는 지 Colab노트북에서 확인해보세요.
저는 10 에폭으로 돌렸을 떄 , Flatten 보다 조금 더 빠르고 덜 정확한 결과가 나왔습니다.

일곱번째 영상, 모델에서 웨이트(가중치)를 저장해주고 모양을 확인해준다.
# shape: (vocab_size, embedding_dim) 로 (10,000,16)이 주어질 것이다.
우리는 시각화 하기 위해 도와줄 기능이 필요하다. 패딩된 토큰을 다시 단어로 해독하기 위해 다음과 같은 과정을 거친다.

그 다음으로 임베딩 시각화해볼 수 있다. 사이트에 접속해서 다운로드받은 파일을 넣으면 아래와 같이 시각화 된다.
사이트 : projector.tensorflow.org/
다운로드 : 밑에 공유한 git_hub 코드 맨 밑에서 두번째 셀 실행하면 다운로드된다.
사이트 왼쪽에 LOAD 누르고 안에 들어가면 첫번쨰버튼에 vecs.tsv, 두번째버튼에 meta.tsv 넣으면 된다. 그리고 나서 왼쪽에 'Sphereuze data' 버튼 누르면 아래와 같은 그림으로 나타난다. (비슷한 단어들이 군집되어있음을 볼 수 있다.)

여덟번째 읽기자료, 5~7번 영상에서 다룬 노트북 제공 gist.github.com/jonhyuk0922/33b171bd80f3c62ffefab26e2d61d985
Course 3 - Week 2 - Lesson 1.ipynb의 사본
Course 3 - Week 2 - Lesson 1.ipynb의 사본. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
아홉번째 영상, 5~7번 영상내용 리뷰
열번째 영상, 지난주 데이터로 돌아간다. sarcasm.json을 다운로드한 후 아래 코드를 실행한다.

열한번째 영상, 우선 추출한 sentences, labels를 아래코드로 trian, test 로 나눠준다.

그 다음엔 아래와 같은 코드로 토크나이저를 정의하고 시퀀스를 정의합니다.

그 다음으로는 모델을 만들어주고 , 모델을 컴파일해줍니다.

이제 30 에폭으로 모델을 학습시켜줍니다. 아래 코드를 실행합니다.

학습이 진행되면 시각화 코드를 통해 결과를 시각화 해줍니다.

결과는 아래와 같이 나타나며, 정확도는 나이스하게 올라가지만, 검증 정확도는 나쁘진않지만 검증 손실을 보면 과적합이 발생하고 있음을 발견할 수 있습니다.

열두번째 영상, 하이퍼파라미터를 조정해서 정확도와 손실의 변화를 확인하시오!!
열세번째 읽기자료, 위에서 사용한 노트북을 제공
열네번째 영상, Pre-tokenized datasets
사전 패키징된 데이터 셋은 종종 일부 작업자가 이미 작업을 수행했을 수 있다.(IMDb도 예외는 아니다.)
여기에서는 단어의 순서가 그 존재만큼이나 중요하다는 것을 보여줄 것입니다.
열다섯번째 읽기자료, 데이터 셋을 다운로드 할 수 있는 깃허브 제공 github.com/tensorflow/datasets/tree/master/docs/catalog
tensorflow/datasets
TFDS is a collection of datasets ready to use with TensorFlow, Jax, ... - tensorflow/datasets
github.com
자세한 내용은 아래 공식홈페이지를 참고해주세요! www.tensorflow.org/datasets/catalog/overview
데이터 세트 | TensorFlow Datasets
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trade
www.tensorflow.org
열여섯번째 영상, subwords text encoder 에 대해 배울 것이다. 우선 Tensorflow 2.x 버전이 필요하니 확인 및 설치해야한다.
colab 노트북 사용중이시라면 상관없다.
아래와 같이 subwords8kf를 사용하여 imdb 데이터를 로드할 수 있다. 그리고 학습, 검증 데이터를 간편하게 불러준다.
import tensorflow_datasets as tfds
imdb, info = tfds.load("imdb_reviews/subwords8k",with_info=True, as_supervised=True)
train_data, test_data = imdb['train'] , imdb['test']
그 다음 아래 코드로 subwords tokenizer를 엑세스 할 수 있다.
tokenizer = info.features['test'].encoder
아래 사이트에서 SubwordTextEncoder 검색해서 공부하기
www.tensorflow.org/datasets/api_docs/python/tfds/features/Text
tfds.features.Text | TensorFlow Datasets
FeatureConnector for text, encoding to integers with a TextEncoder.
www.tensorflow.org
열여덟번째 영상, subwords text encoder는 에폭당 학습 시간도 길었고, 결과도 좋지 못했다. 이것에 대해선 다음주에 더 좋게할 방법을 배울 것이다.
열아홉번째 읽기자료, subwords text encoder 사용하는 노트북 제공 gist.github.com/jonhyuk0922/78516ff4d83aa165f5b277eac6873a40
Course 3 - Week 2 - Lesson 2.ipynb의 사본
Course 3 - Week 2 - Lesson 2.ipynb의 사본. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
스무번째 영상, 위에 노트북 코드 리뷰
* 강의에서는 2.00-alpha 버전을 권장하지만 지금 2.4.1버전이라 2.1 이상 버전 사용해야한다. (2.0에선 API 지원이 안된다)
* 데이터 로드하는 코드 실행했을 때 아래와 같이 경고하지만 저기 들어가도 데이터 로드하는 건 안나와있다 ...
WARNING:absl:TFDS datasets with text encoding are deprecated and will be removed in a future version. Instead, you should use the plain text version and tokenize the text using `tensorflow_text` (See: https://www.tensorflow.org/tutorials/tensorflow_text/intro#tfdata_example)
gist.github.com/jonhyuk0922/e978df658af8fe219b899679156b4535
Course 3 - Week 2 - Lesson 3.ipynb의 사본
Course 3 - Week 2 - Lesson 3.ipynb의 사본. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
퀴즈에서 배운 점
-IMDB sub Words dataset 이용했을 때 결과가 잘 안나온 이유 : 하위 단어(sub words)처리할 때 순서가 훨씬 더 중요해지는데 이 데이터 셋은 단어 위치를 무시한다.
* 과제 : BBC 뉴스 아카이브 카테고리 분류 예측해보기
gist.github.com/jonhyuk0922/45a23bb5f35b46f02ded0d2d883083c5
Course 3 - 2주차과제(BBC Archive Classification)
Course 3 - 2주차과제(BBC Archive Classification). GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
노트북에서 추출한 tsv 파일을 projector.tensorflow.org/ 에 넣었을 때 결과는 아래와 같다.
Embedding projector - visualization of high-dimensional data
Visualize high dimensional data.
projector.tensorflow.org
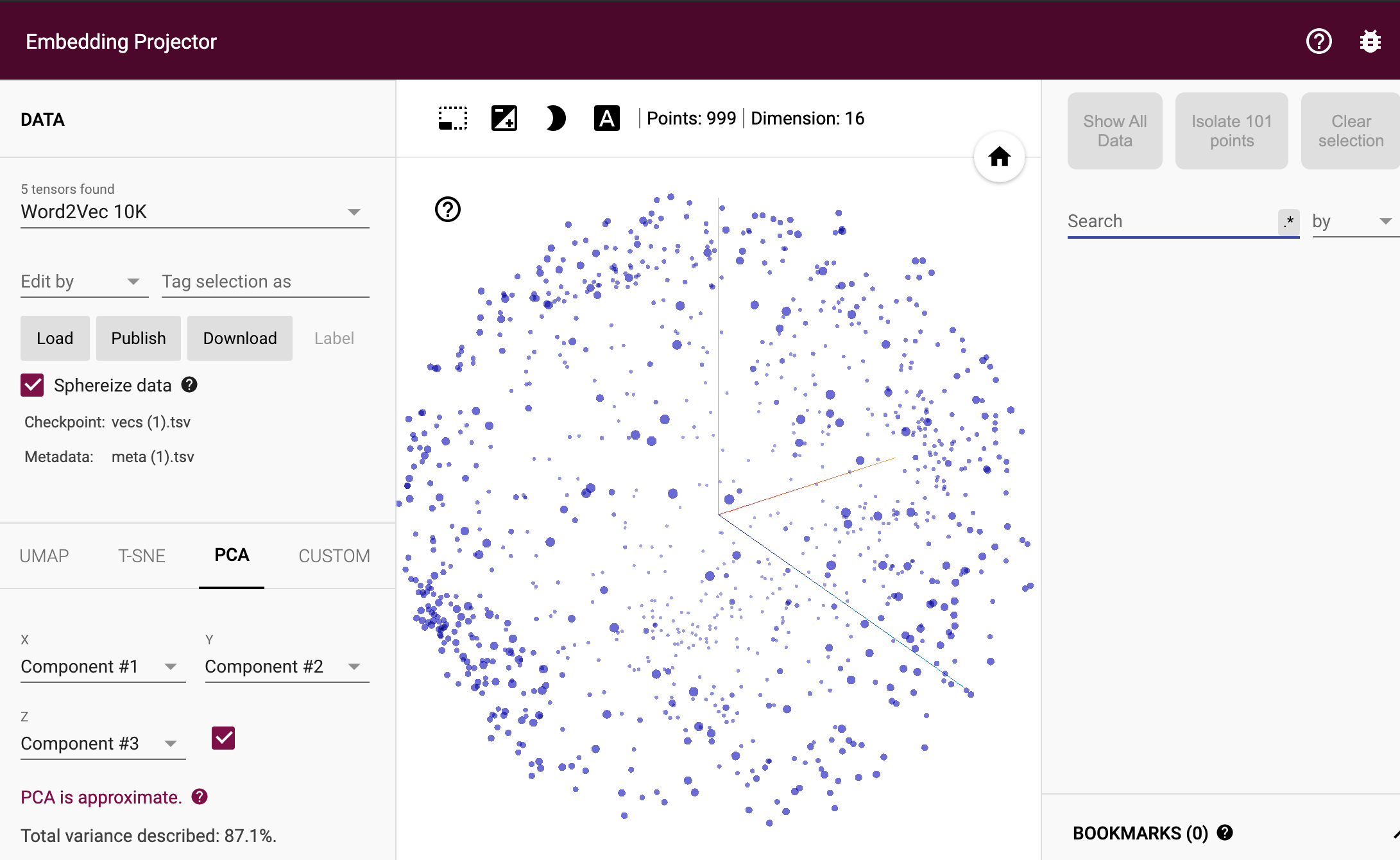
위에서 search에 label을 넣으면 주변 단어들을 보여준다. 재밌으니 코드 돌려보시고 프로젝트에서확인해보시는 거 추천드린다!

'머신러닝 & 딥러닝 공부 > Tensorflow' 카테고리의 다른 글
| [Tensorflow dev 자격증] Sequence models and literature (0) | 2021.02.25 |
|---|---|
| [Tensorflow dev 자격증] Sequence models (0) | 2021.02.24 |
| [NLP 오류해결] Stopword(불용어) Tensorflow 2.0 에서 사용 시 import 오류 해결 방법 (0) | 2021.02.15 |
| [Tensorflow dev 자격증] Sentiment in text (0) | 2021.02.15 |
| [Tensorflow dev 자격증] Multiclass Classifications (0) | 2021.02.13 |



