
안녕하세요
27년차 진로탐색꾼 조녁입니다!
오늘은 텐서플로우 자격증 과정 두번째 강좌인
' Convolutional Neural Networks in TensorFlow '
3주차 강의(Transfer Learning) 및 자료를 공부했습니다.
전이학습(Transfer Learning)은 전에 코드프레소에서 인공지능 실무과정들을 때 신기해했던 개념이고, 꿀팁과도 같은 기능이었어요.
첫번째 영상 , 이번 3주차에서는 전이학습에 대해 배우는데, 지금처럼 딥러닝 기술이 빠르게 발전하도록 도운 효놈(?)이 아닌가 생각합니다.
우리는 단지 텐서플로우 몇줄로 이것을 구현할 수 있습니다. 전이학습은 이미 다른 이가 학습해서 얻은 가중치를 가져오는 것입니다. 내가 큰 데이터를 다룰 수 있는 인프라가 없을 때 이러한 전이학습을 사용한다면 속도와 정확도 측면에서 큰 도움을 받을 수 있습니다. 디음 강의에서 본격적으로 배우기 시작해요!
두번째 영상, 우리는 아래와 같이 CNN을 구성하고 데이터를 학습시키는 과정을 배웠다. 추가로 오버피팅을 피하기 위해 학습 데이터를 증강하는 것도 배웠다. 그러나 이 과정을 누군가가 나보다 훨씬 훌륭하게 이미 해놓은 것이 있다면???!!

만약, 누군가가 당신보다 더 조밀한 모델을 설계해서 훨씬 더 큰 데이터를 학습시켜놓은 모델이 있다면 우리는 다시 학습하지 않고 특성을 잠궈서 추출할 수 있다. 이것이 전이학습의 컨셉이다.
물론 원한다면 특정 컨볼루션 레이어는 새로 원하는 데이터로 학습시킬 수도 있다. (그것은 Fine Tunning이라고 부른다.)
세번째 읽기자료, 이제 다음 강의에서 전이학습에 대해 코드를 짜볼것이다. 아래 노트북을 우리는 사용할 것이다.
gist.github.com/jonhyuk0922/621bcd06529a03329c19337a1d16693f
Course 2 - Part 6 - Lesson 3 - Notebook.ipynb의 사본
Course 2 - Part 6 - Lesson 3 - Notebook.ipynb의 사본. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
레이어를 불러올 때 잠그는 것에 대해 더 배우고자한다면 아래 텐서플로우 공식홈페이지를 참고하시오. (예시도 있어 보기 좋다.)
www.tensorflow.org/tutorials/images/transfer_learning
사전 학습된 ConvNet을 이용한 전이 학습 | TensorFlow Core
이 튜토리얼에서는 사전 훈련된 네트워크에서 전이 학습을 사용하여 고양이와 개의 이미지를 분류하는 방법을 배우게 됩니다. 사전 훈련된 모델은 이전에 대규모 데이터셋에서 훈련된 저장된
www.tensorflow.org
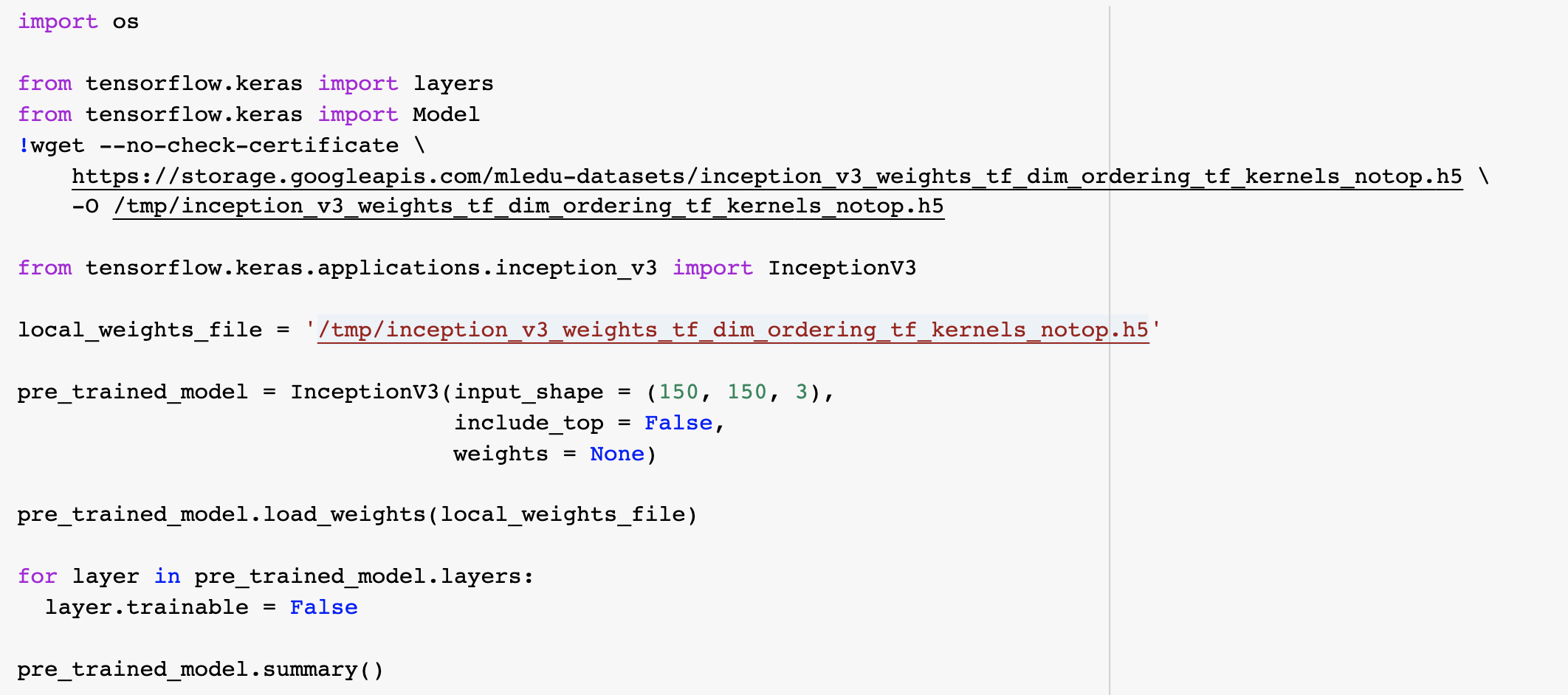
네번째 영상, 위에 올려놓은 Course2-part6-lesson3 노트북을 보자. 입력부터 살펴보면, Keras.layers API를 이용하여 사용할 레이어와 재교육할 레이어를 선택합니다. 이 과정을 아래 코드와 함께보면 url에는 학습된 모델의 가중치가 들어있다.
그리고 inception_v3 모델 상단에는 완전히 연결된 층이 있으므로, Include_top은 false로 설정합니다. 그러면 이것을 무시하고 곧바로 컨볼루션으로 연결된다.
모델의 요약(pre_trained_model.summary())은 노트북에서 직접 보는 것을 추천한다. (어엄청 길다.)
다섯번째 읽기자료, 이전 영상에서 이미 존재하는 모델로부터 특징을 추출하는 것을 봤다. 이제는 맨끝에 있는 DNN을 당신의 데이터로 학습하는 것을 배울 것이다. 다음 영상으로 가시오.
여섯번째 영상, 모든 레이어에는 이름이 있기에 마지막 레이어를 찾는다. 그러고는 컨볼루션을 3*3에서 7*7로 바꾼 후 DNN을 만들어 준다. 이때, Dense를 1,024로 굉장히 조밀하게 해준다.
위와 같이 모델을 정의한 후 전과같이 ImageDataGenerator를 사용하여 데이터 증강을 한후, 디렉토리로부터 데이터를 불러주고 모델을 학습시킨다. 결과는 아래와 같이 어마어마한 오버피팅이 일어난다. 이에 대한 햬결책 및 이유는 다음에서 배울 것이다.

일곱번째 읽기자료, Using dropouts!
드랍아웃의 컨셉은 신경망에서 임의의 수의 뉴런을 제거한다는 것이다.
아래 두가지 이유로 드랍아웃은 잘 작동한다.
1. 종종 인접한 뉴런이 비슷한 가중치를 가져서 오버피팅을 일으키는데 그것들을 제거하면서 줄일 수 있다.
2. 종종 뉴런이 이전 계층에 있는 뉴런의 입력 값을 초과해 결과적으로 지나치게 전문화된다. 이것을 막을 수 있다.
앤드류의 강의 링크를 줬는데 나는 그냥 텐서플로우 공식 홈페이지 설명이 더 나은 것 같다.
www.youtube.com/watch?v=ARq74QuavAo
www.tensorflow.org/api_docs/python/tf/keras/layers/Dropout
tf.keras.layers.Dropout | TensorFlow Core v2.4.1
Applies Dropout to the input.
www.tensorflow.org
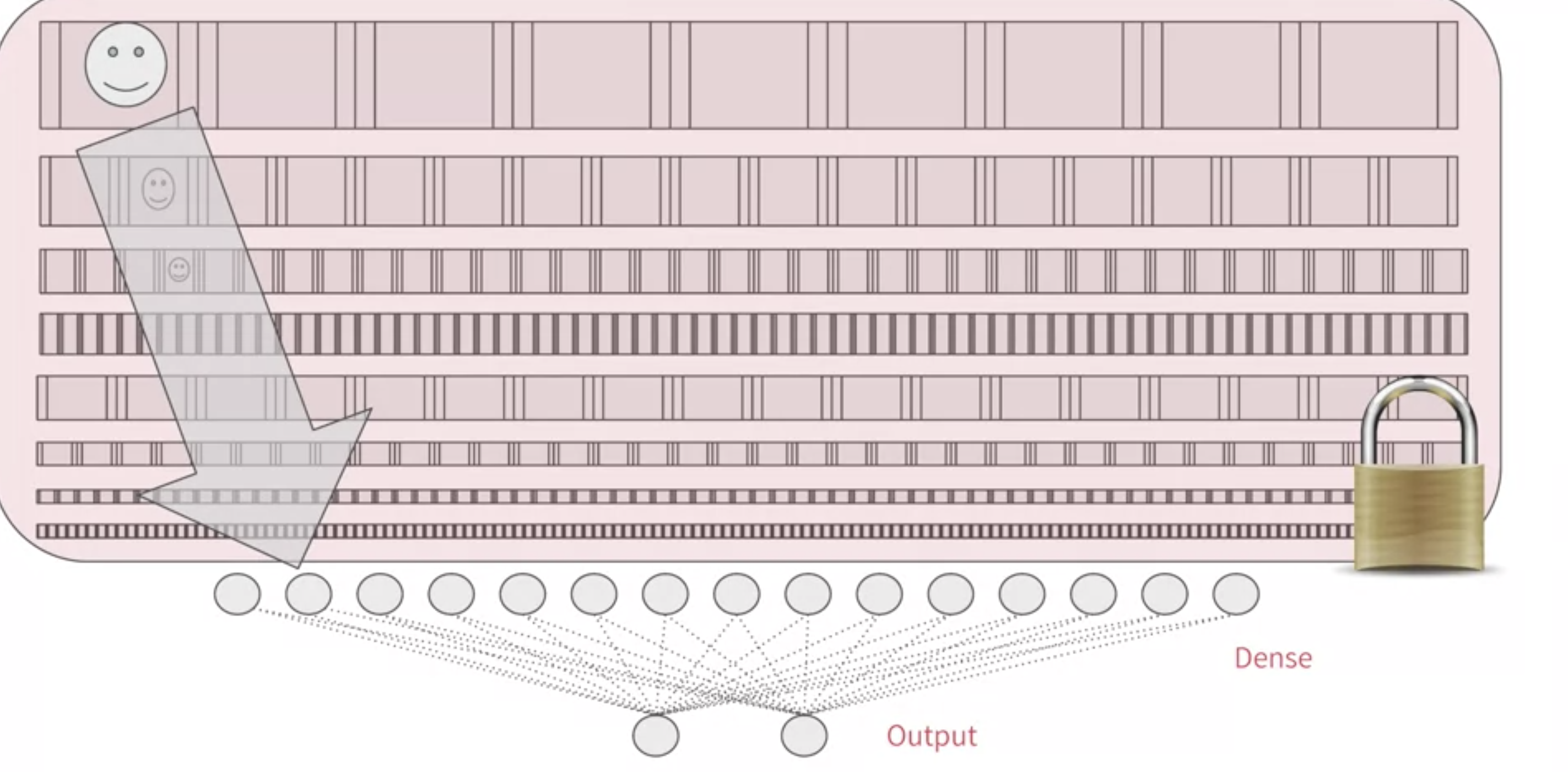
여덟번째 영상, 우리는 전이학습과 증강을 통해 개-고양이 분류 모델을 돌려봤다. 그러나 좋지 못한 과대적합이 발생했다.

우리가 사용한 조밀한 모델이 왼쪽 사진과 같을 때,
일부를 떨어 뜨리면 검정색부분을 제거한 것과 같다.
여기서 각각의 뉴런들은 이웃한 뉴런들에 큰 영향을 미치지 않는다.
이것은 잠재적인 오버피팅을 제거하는 효과가 있다.
아래 기존 코드에 드랍아웃 코드를 추가한 코드가 있습니다. 여기서 드랍아웃은 0~1로 제거할 뉴런의 비율을 나타냅니다.

드랍아웃의 효과는 위에 사용하기 전 그림4와 아래 그림6를 비교하면 볼 수 있다.

아홉번째 읽기자료, 전이학습과 드랍아웃을 이용한 정규화를 살펴봤으니, 개-고양이 분류 시나리오에 적용해보자.
gist.github.com/jonhyuk0922/621bcd06529a03329c19337a1d16693f
Course 2 - Part 6 - Lesson 3 - Notebook.ipynb의 사본
Course 2 - Part 6 - Lesson 3 - Notebook.ipynb의 사본. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
열번째 영상, 우리가 이번주 배운 것에 대해 위 깃허브 노트북을 쭉 함께 살펴봤다.
1. 학습된 가중치를 불러와서 새로운 인스턴스를 인스턴스화합니다.
2. 그리고 컨볼루션 레이어 중 하나를 입력 레이어로 가져온 다음 출력값을 저장합니다. 그리고 이것을 last output으로 설정한 후 이것을 input으로 사용하는 모델을 설정합니다.
(즉, 다른 모델의 가중치를 가져오되, 우리에게 주어진 이미지에 맞게 효과적으로 기억하기 위해 컨볼루션 레이어를 설정하기 위한 것이다.)
3. DNN을 설정하는데 , 중간에 드랍아웃을 넣어준다. 그리고 모델을 컴파일 한다.
4. 개-고양이 데이터를 ImageDataGenerator를 이용해 디렉토리별로 저장해준다. 증강도 이용한다.
(두개의 클래스(학습,벨리데이션)로 각각 2,000장 1,000장이 분류된다.)
5.history 변수로 학습을 할당한 후 진행한다. 에폭은 20을 사용했다.
6. 그래프를 살펴보면, training acc와 val acc이 동반 상승하는 것을 확인할 수 있다.
즉, train_acc와 val_acc가 동시에 상승하는 것을 보아 오버피팅을 벗어났음을 확인할 수 있다.
열한번째 읽기자료, 이번주 전이학습과 드랍아웃을 배웠다.
전이학습 : 효과적으로 학습된 컨볼루션을 '기억'한다. 그리고 자체 DNN을 그 아래 붙여서 만든 모델을 사용하는 것
드랍아웃 : 네트워크에 과도하게 전문화하고 오버피팅이 발생하는 것을 막기 위해 뉴런 수를 줄여준다.
퀴즈 정답노트
<배운점>
-드랍아웃 0.2는 20% 뉴런 날린다는 것을 의미한다. 만약 비율이 너무 높으면 오히려 특징을 다 날려버려서 비효율적일 수 있다.
-전이학습할 때 잠그기 위해 "layer.trainable = false"를 사용해서 할 수 있다.
-드랍아웃이 효과적으로 오버피팅을 줄이는 이유 : 이웃한 뉴런은 비슷한 가중치를 가지는데 이를 줄임으로써 특정 정보에 전문화되는 걸 막기 때문이다.
이 외에 두 문제는 기억했으면 해서 통으로 기록합니다.
1. How do you change the number of classes the model can classify when using transfer learning? (i.e. the original model handled 1000 classes, but yours handles just 2)
1) Ignore all the classes above yours (i.e. Numbers 2 onwards if I'm just classing 2)
2) Use all classes but set their weights to 0
3) When you add your DNN at the bottom of the network, you specify your output layer with the number of classes you want
4) Use dropouts to eliminate the unwanted classes
풀이: 3번, 분류할 클래스는 네트워크 하단 DNN을 추가할 때, 원하는 클래스 수로 출력 레이어를 지정한다.
2. Can you use Image Augmentation with Transfer Learning Models?
1) No, because you are using pre-set features
2) Yes, because you are adding new layers at the bottom of the network, and you can use image augmentation when training these
풀이 : 2번, 모델 끝에 자체 DNN을 추가하는데,이것을 학습할 때 증강한 데이터를 통해 학습할 수 있다.
* 과제 : 전이학습 + 드랍아웃 이용해서 사람-말 분류 모델 만들기!
gist.github.com/jonhyuk0922/5a5e78858223752fc7b3afb1da74fb10
Course2-3주차 과제(Transfer learning &Drop out)
Course2-3주차 과제(Transfer learning &Drop out). GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
추가 내용
Dropout 원리 : 드랍아웃은 학습데이터에서, 가까이 있는 뉴런들이 비슷한 가중치를 가지므로, 오버피팅을 피하기 위해 그것들을 제하여 주는 것이다. 그런데 예측할 때는 모든 뉴런을 다 켜주기 때문에, 재하여 주고 학습한 만큼 테스트할 때도 뺴줘야하는데 그게 복잡하니까 실제 딥러닝 라이브러리들은 학습데이터에서 드롭된 뉴런의 비율만큼 출력을 키워준다.
Transfer Learning : feature를 불러오는게 아니라 , weights 를 가져오는 것
참고자료
https://www.youtube.com/watch?v=oupV1qlLQiE&list=PLJN246lAkhQiHms1uA-x886dg1JJfne15&index=6
'머신러닝 & 딥러닝 공부 > Tensorflow' 카테고리의 다른 글
| [Tensorflow dev 자격증] Sentiment in text (0) | 2021.02.15 |
|---|---|
| [Tensorflow dev 자격증] Multiclass Classifications (0) | 2021.02.13 |
| [Tensorflow dev 자격증] Exploring Larger Dataset (0) | 2021.02.12 |
| [Tensorflow dev 자격증] Augmentation : A technique to avoid overfitting (0) | 2021.02.11 |
| [Tensorflow dev 자격증] Using Real-world Images (0) | 2021.02.09 |



