https://link.coupang.com/a/NS8jv
Apple 2022 아이패드 에어 5세대
COUPANG
www.coupang.com

안녕하세요~
27년차 진로탐색꾼 조녁입니다!!
오늘은 음성파일을 인식하고 거기서 특징추출하는 기초적인 내용부터
추출한 특징들을 통해 노래의 장르를 분류하는 모델과 비슷한 장르의 노래를 추천해주는 알고리즘을 살펴보겠습니다!
Tensorflow Dev 공부할 때, 텍스트를 LSTMs 로 학습시켜서 시를 작성해본 적이 있는데 음성파일을 다루는 건 처음이네요!
* 오늘의 과제 : 노래 장르 분류 알고리즘 & 간단한 추천 알고리즘 구현해보기!
1. 데이터셋 다운로드
: 우선 저는 kaggle 데이터 셋을 사용하였고, 직접 다운로드 받아 사용할 수도 있지만, kaggle 과 연동을 통해 colab으로 직접 데이터셋을 불러와 사용해보겠습니다. (자세한 연동방법은 추후 포스팅 하겠습니다.)
!pip install kaggle #colab에서 리눅스 명령어를 사용할 때는 !을 붙여준다.
from google.colab import files
files.upload() #kaggle.json upload
#colab 내 kaggle 디렉토리 생성
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/kaggle.json
#permission warning 방지
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download -d andradaolteanu/gtzan-dataset-music-genre-classification
!unzip -q gtzan-dataset-music-genre-classification.zip
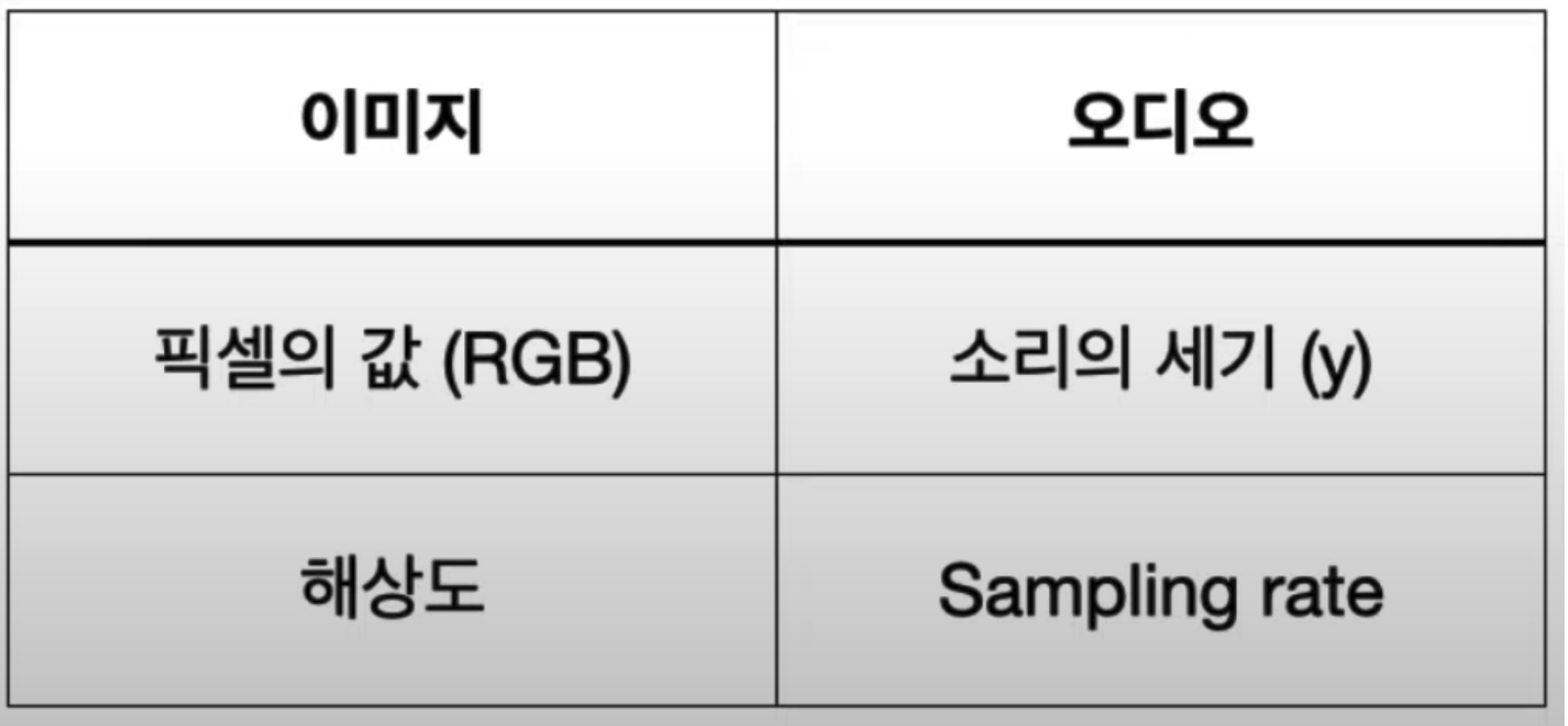
2. 오디오 파일 이해하기 : 숫자로 이루어짐
* y : 소리가 떨리는 세기(진폭)를 시간 순서대로 나열한 것
* Sampling rate: 1초당 샘플의 개수, 단위 1초당 Hz 또는 kHz
2-1. 기본값 확인
: 저는 파이썬에서 음원데이터를 분석해주는 librosa 라이브러리를 사용하였습니다. 우선 래게장르 36번 wav 파일을 불러와서 기본적인 것들을 프린트해봅니다.
import librosa
y , sr = librosa.load('Data/genres_original/reggae/reggae.00036.wav') # librosa.load() : 오디오 파일을 로드한다.
print(y)
print(len(y))
print('Sampling rate (Hz): %d' %sr)
print('Audio length (seconds): %.2f' % (len(y) / sr)) #음악의 길이(초) = 음파의 길이/Sampling rate
@ 살펴봐야할 것은 y(소리의 세기) 값이 숫자로 이루어졌다는 것과, 음악의 길이 = 음파 길이/sr 이라는 점입니다.
2-2.음악 들어보기
: 아래 GUI 형태로 출력된 결과를 확인할 수 있다. 버튼을 누르면 음악이 실행됩니다. (신기했다.. 방금 분명 숫자였는데)
import IPython.display as ipd
ipd.Audio(y, rate=sr)
2-3. 2D 음파 그래프
import matplotlib.pyplot as plt
import librosa.display
plt.figure(figsize =(16,6))
librosa.display.waveplot(y=y,sr=sr)
plt.show()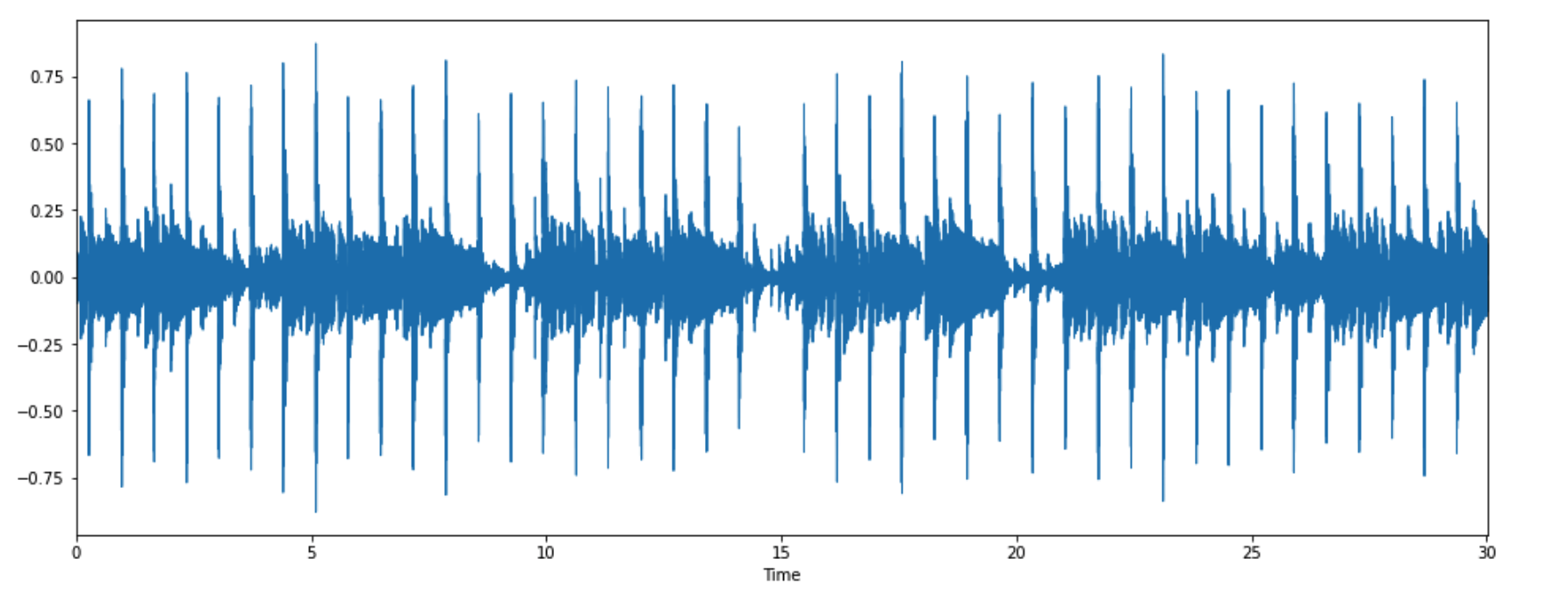
2-4. Fourier Transform(푸리에 변환)
* 시간 영역 데이터를 주파수 영역으로 변경 : time(시간) domain -> frequency(진동수) domain 변경 시 얻는 정보가 많아져 분석 용이.
* y축: 주파수(로그 스케일)
* color축:데시벨(진폭)
import numpy as np
D = np.abs(librosa.stft(y, n_fft=2048, hop_length=512)) #n_fft : window size / 이 때, 음성의 길이를 얼마만큼으로 자를 것인가? 를 window라고 부른다.
print(D.shape)
plt.figure(figsize=(16,6))
plt.plot(D)
plt.show()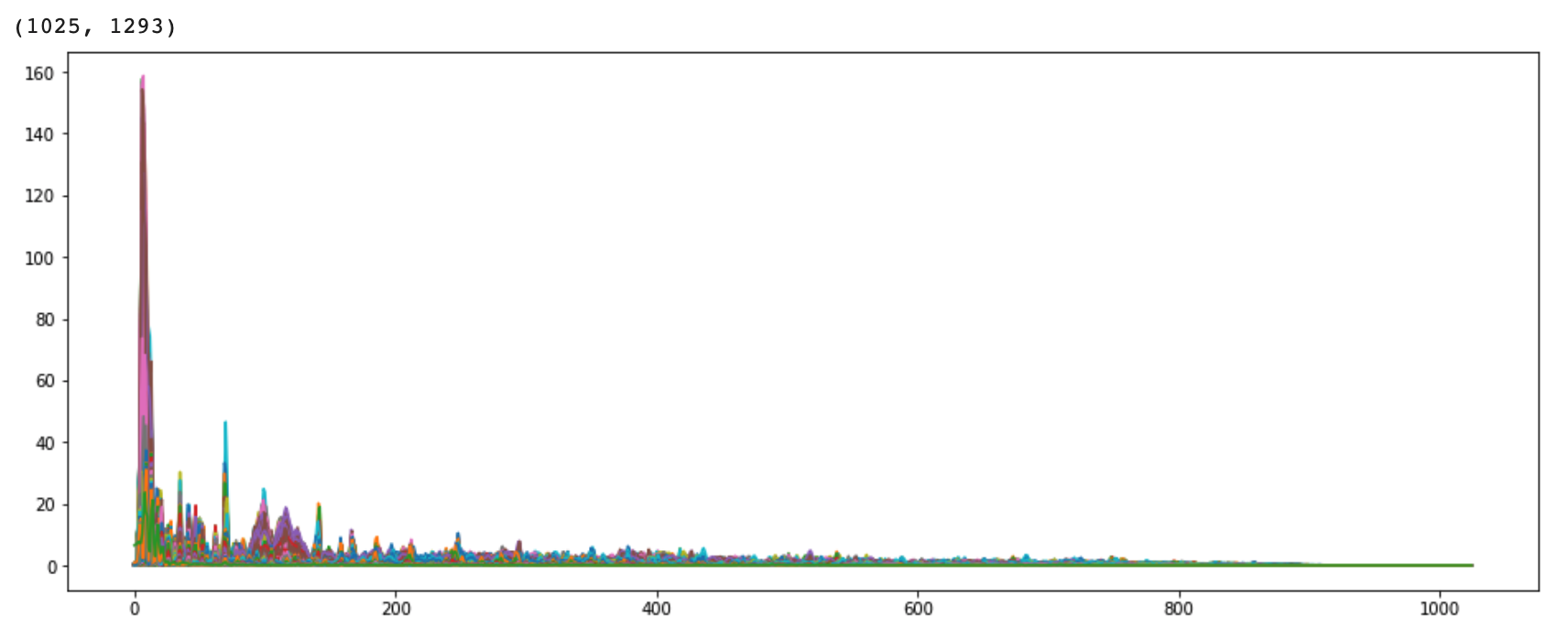
2-5.Spectogram
* 시간에 따른 신호 주파수의 스펙트럼 그래프
* 다른 이름 : Sonographs, Voiceprints, Voicegrams
DB = librosa.amplitude_to_db(D, ref=np.max) #amplitude(진폭) -> DB(데시벨)로 바꿔라
plt.figure(figsize=(16,6))
librosa.display.specshow(DB,sr=sr, hop_length=512, x_axis='time', y_axis='log')
plt.colorbar()
plt.show()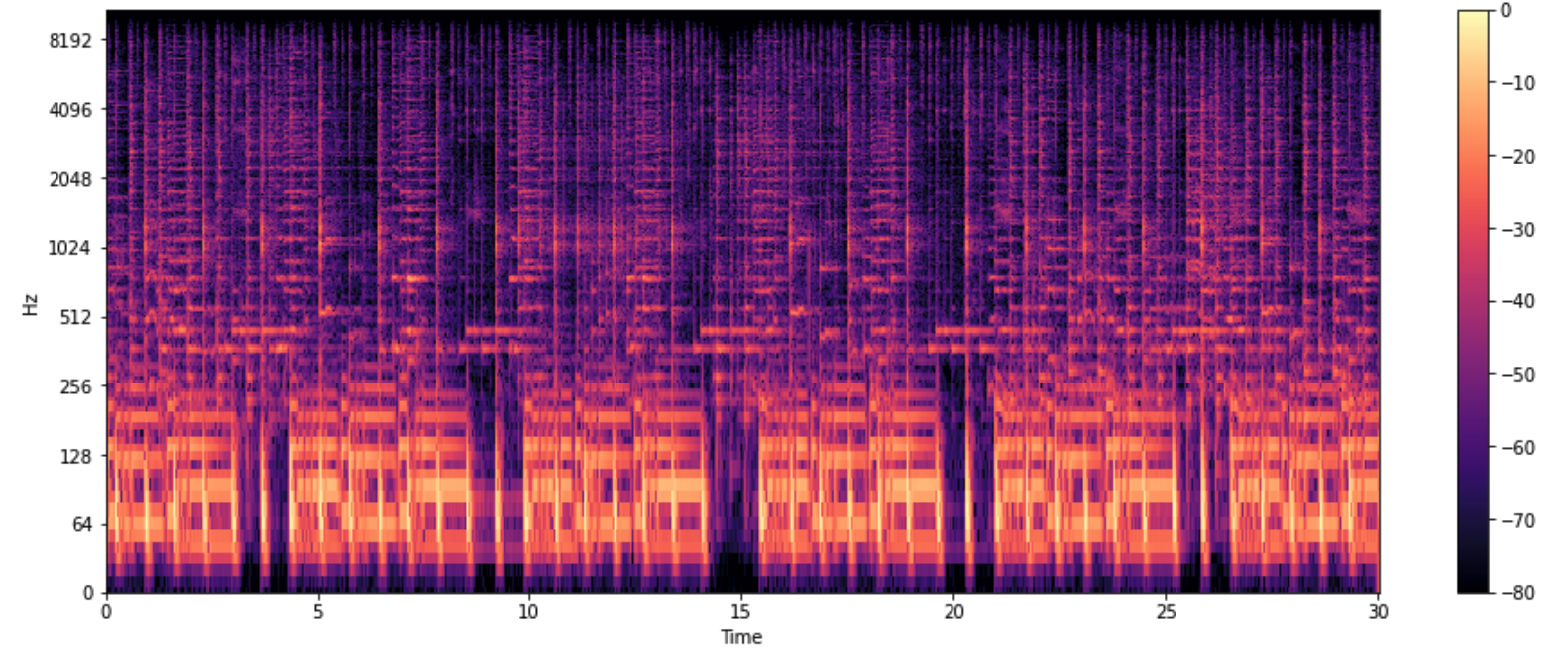
2-6. Mel Spectogram
*(인간이 이해하기 힘든) Spectogram의 y축을 Mel Scale로 변환한 것(Non-linear transformation)
*Mel Scale : https://newsight.tistory.com/294
위 사이트에 상세하게 나와있으니 시간되실 때 한번 읽어보시는 것 추천드립니다! 바쁘신 분들은 Mel 로 검색해서 나오는 부분들만 보세요!
S = librosa.feature.melspectrogram(y, sr=sr)
S_DB = librosa.amplitude_to_db(S, ref=np.max)
plt.figure(figsize=(16,6))
librosa.display.specshow(S_DB, sr=sr,hop_length=512, x_axis='time',y_axis='log')
plt.colorbar()
plt.show()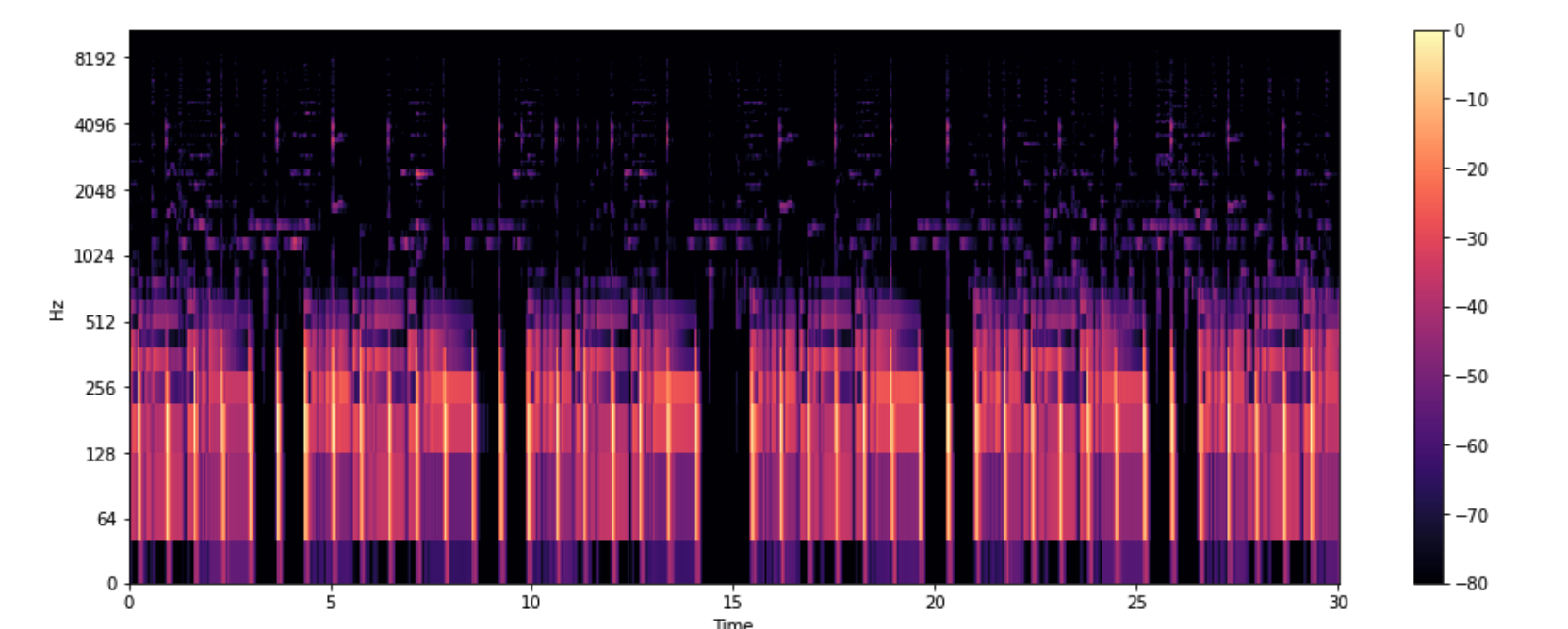
2-7. 레게 vs 클래식 Mel Spectogram
감이 잘 안와서, 위의 레게 장르 Mel Spectogram 과 비교하기 위해 클래식 장르 Mel Spectogram도 찍어봤습니다.
y, sr = librosa.load('Data/genres_original/classical/classical.00036.wav')
y, _ = librosa.effects.trim(y)
S = librosa.feature.melspectrogram(y, sr=sr)
S_DB = librosa.amplitude_to_db(S, ref=np.max)
plt.figure(figsize=(16,6))
librosa.display.specshow(S_DB, sr=sr,hop_length=512, x_axis='time',y_axis='log')
plt.colorbar()
plt.show()
3. 오디오 특성 추출(Audio Feature Extraction)
3-1. Tempo(BPM)
tempo , _ = librosa.beat.beat_track(y,sr=sr)
print(tempo)
3-2. Zero Crossing Rate
* 음파가 양에서 음으로 또는 음에서 양으로 바뀌는 비율
* 간단하지만 많이 쓰인다.
zero_crossings = librosa.zero_crossings(y, pad=False)
print(zero_crossings)
print(sum(zero_crossings)) # 음 <-> 양 이동한 횟수
조금 더 확대해서 살펴보면 아래와 같습니다. 저는 9000~ 9040 사이 값을 살펴봤습니다.
이 때 Zero Crossing은 0이 되는 선을 지나친 횟수를 의미합니다.
n0 = 9000
n1 = 9040
plt.figure(figsize=(16,6))
plt.plot(y[n0:n1])
plt.grid()
plt.show()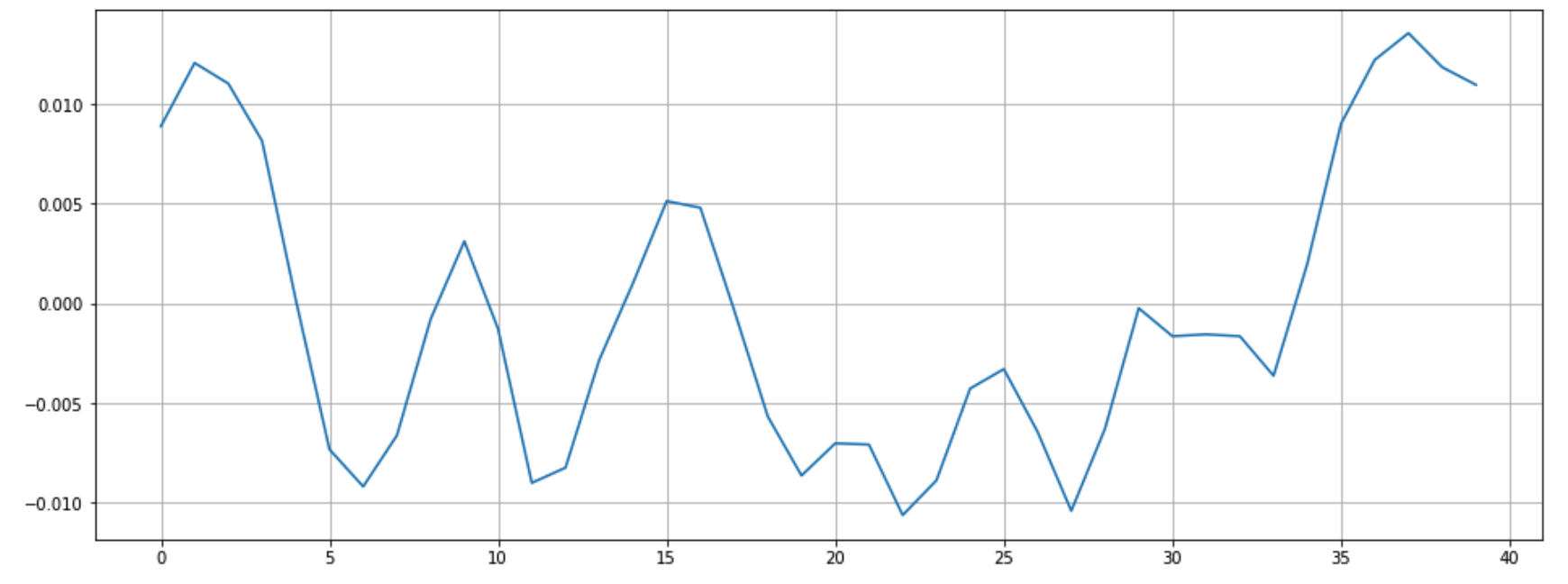
눈으로 Zero Crossing을 세보면 6이 나옵니다. 코드로 찍어보면
zero_crossings = librosa.zero_crossings(y[n0:n1], pad=False) #n0 ~ n1 사이 zero crossings
print(sum(zero_crossings))
마찬가지로 6이 나옵니다.
3-3. Harmonic and Percussive Components
* Harmonics : 사람의 귀로 구분할 수 없는 특징들(음악의 색깔)
* Percussives: 리듬과 감정을 나타내는 충격파
y_harm, y_perc = librosa.effects.hpss(y)
plt.figure(figsize=(16,6))
plt.plot(y_harm, color='b')
plt.plot(y_perc, color='r')
plt.show()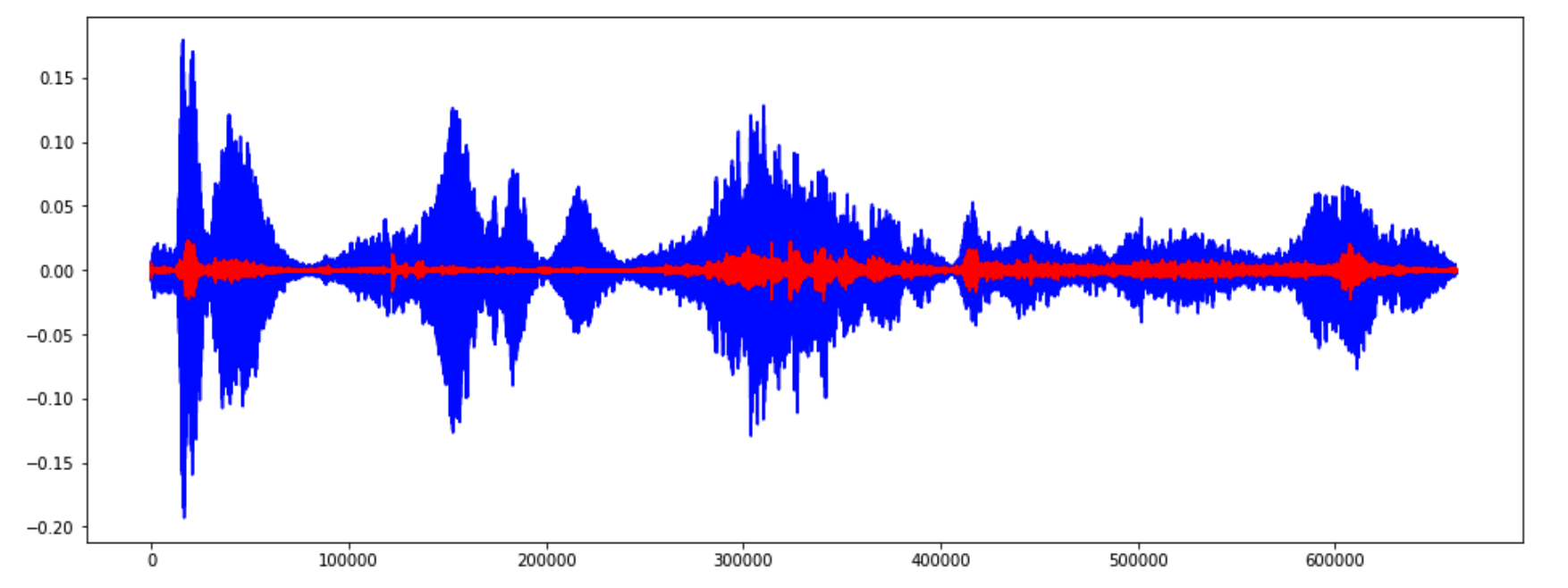
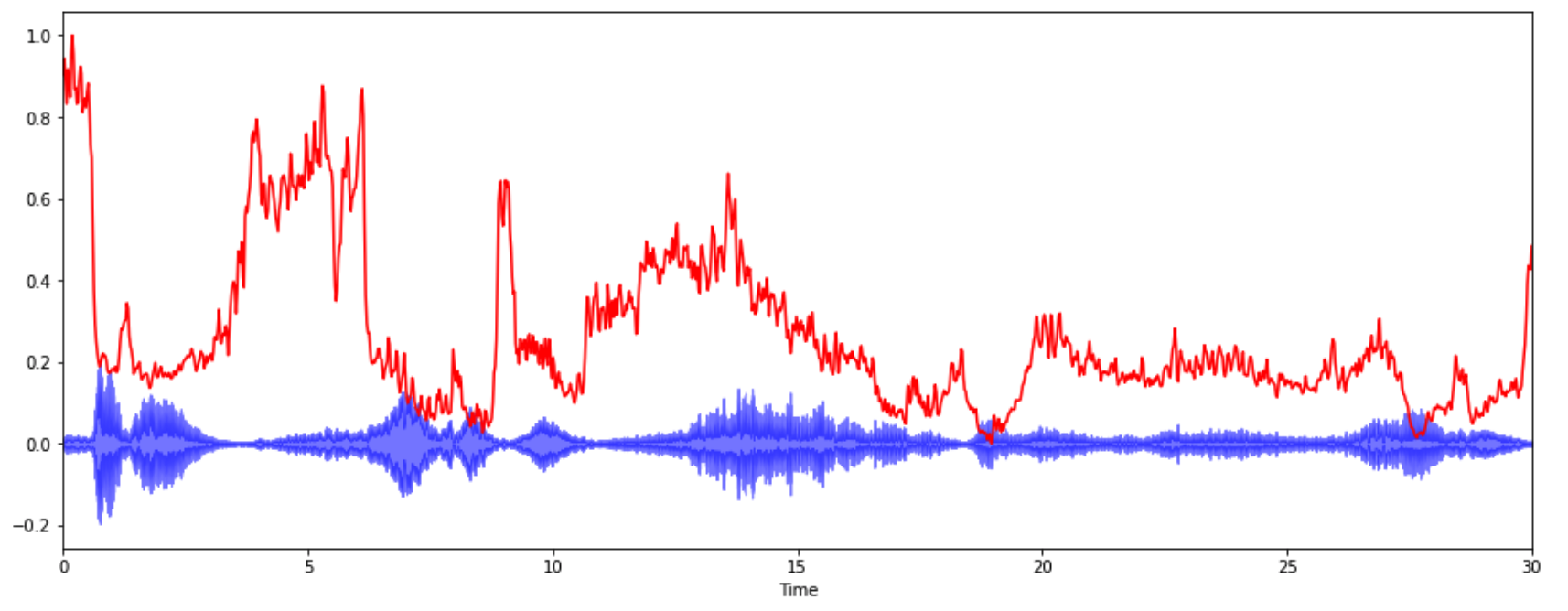
3-4.Spectral Centroid
* 소리를 주파수 표현했을 때, 주파수의 가중평균을 계산하여 소리의 "무게 중심"이 어딘지를 알려주는 지표
* 예를 들어, 블루스 음악은 무게 중심이 가운데 부분에 놓여있는 반면, 메탈 음악은 (끝 부분에서 달리기 때문에) 노래의 마지막 부분에 무게 중심이 실린다.
spectral_centroids = librosa.feature.spectral_centroid(y, sr=sr)[0]
#Computing the time variable for visualization
frames = range(len(spectral_centroids))
# Converts frame counts to time (seconds)
t = librosa.frames_to_time(frames)
import sklearn
def normalize(x, axis=0):
return sklearn.preprocessing.minmax_scale(x, axis=axis) #sk.minmax_scale() : 최대 최소를 0 ~ 1 로 맞춰준다.
plt.figure(figsize=(16,6))
librosa.display.waveplot(y, sr=sr, alpha=0.5, color='b')
plt.plot(t, normalize(spectral_centroids), color='r')
plt.show()
3-5. Spectral Rolloff
* 신호 모양을 측정한다.
* 총 스펙트럴 에너지 중 낮은 주파수(85% 이하)에 얼마나 많이 집중되어 있는가
spectral_rolloff = librosa.feature.spectral_rolloff(y, sr=sr)[0]
plt.figure(figsize=(16,6))
librosa.display.waveplot(y,sr=sr,alpha=0.5,color='b')
plt.plot(t, normalize(spectral_rolloff),color='r')
plt.show()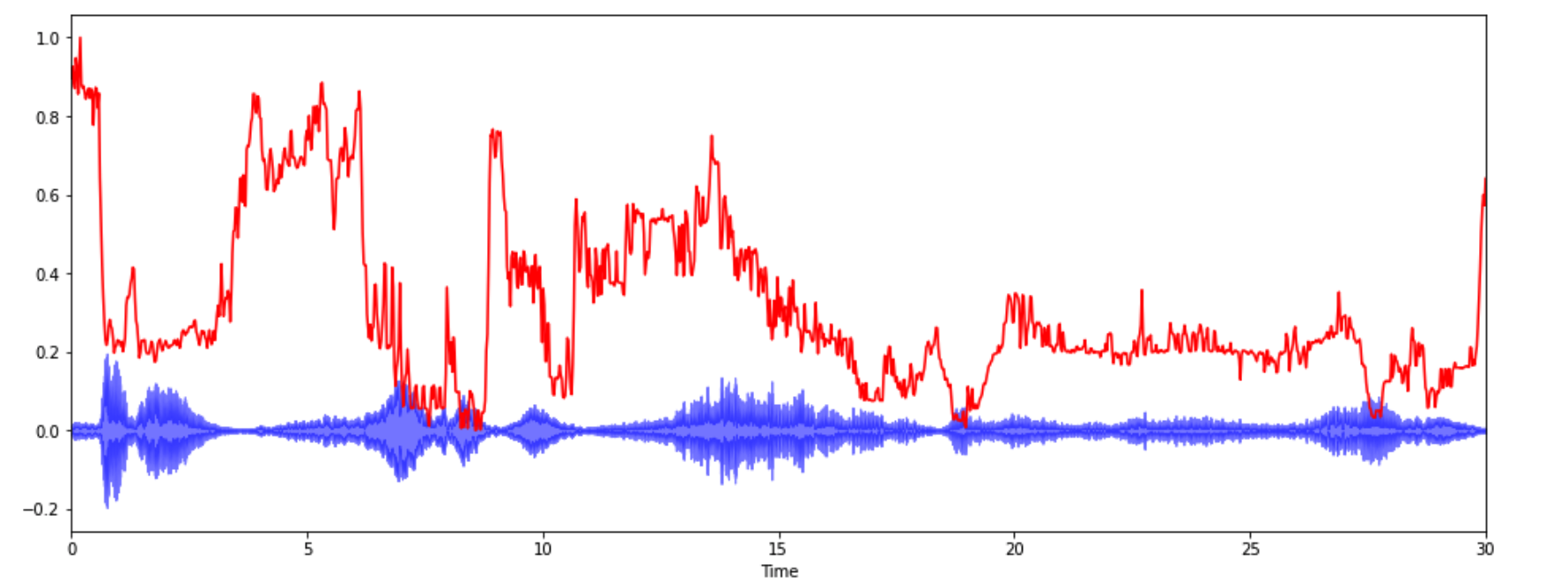
3-6. Mel-Frequency Cepstral Coefficients(MFCCs)
* MFCCs는 특징들의 작은 집합(약 10-20)으로 스펙트럴 포곡선의 전체적인 모양을 축약하여 보여준다.
* 사람의 청각 구조를 반영하여 음성 정보 추출
* https://tech.kakaoenterprise.com//66
위에 카카오엔터가 운영하는 기술블로그에 아주 상세하게 나와있습니다! 시간 있으신 분들은 한 번 보시는 걸 추천해요!
(위에 블로그 보시면 사실 저 위에 달았던 블로그는 안보셔도 될 것 같아요!)
mfccs = librosa.feature.mfcc(y, sr=sr)
mfccs = normalize(mfccs,axis=1)
print('mean: %.2f' % mfccs.mean())
print('var: %.2f' % mfccs.var())
plt.figure(figsize=(16,6))
librosa.display.specshow(mfccs,sr=sr, x_axis='time')
plt.show()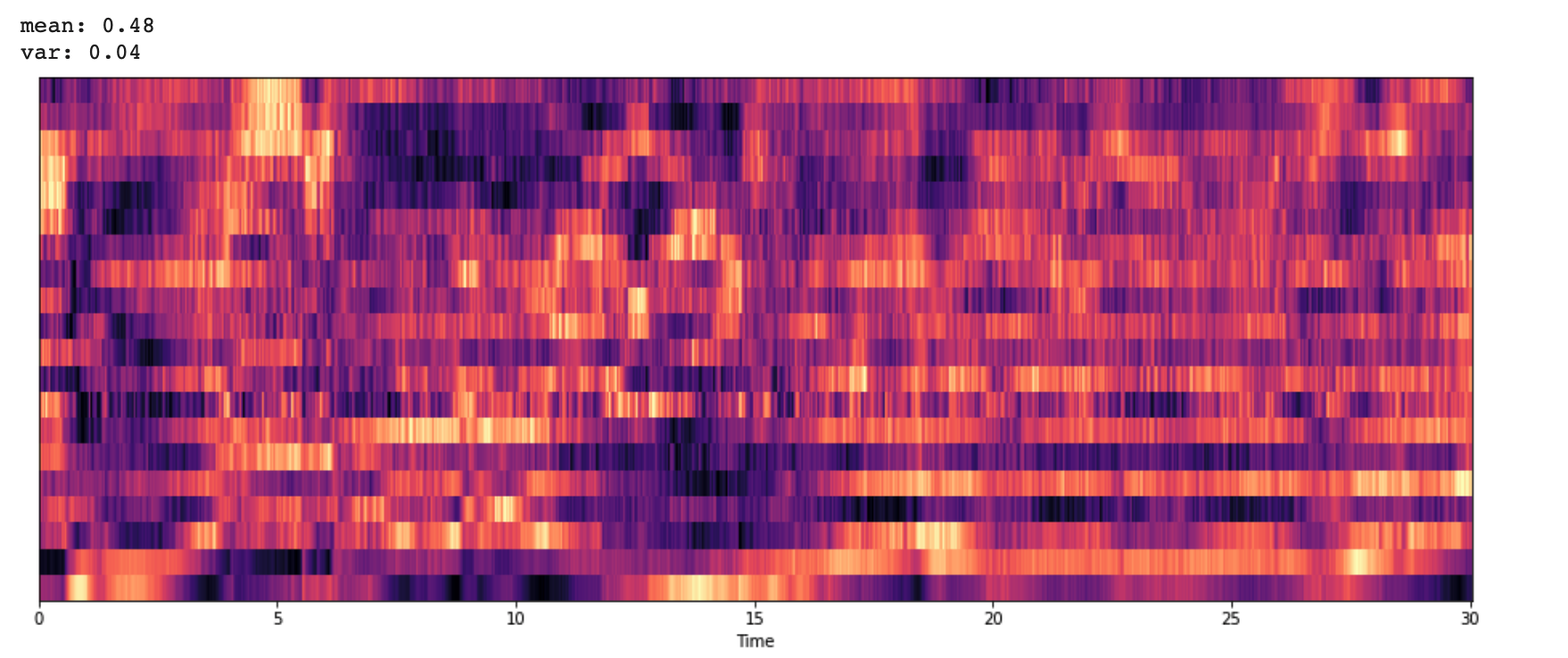
3-7. Chroma Frequencies
* 크로마 특징은 음악의 흥미롭고 강렬한 표현이다.
* 크로마는 인간 청각이 옥타브 차이가 나는 주파수를 가진 두 음을 유사음으로 인지한다는 음악이론에 기반한다. -> 화음 인식 good
* 모든 스펙트럼을 12개의 Bin으로 표현한다.
* 12개의 Bin은 옥타브에서 12개의 각기 다른 반응(Semitones(반음) = Chroma)을 의미한다.
chromagram = librosa.feature.chroma_stft(y, sr=sr, hop_length=512)
plt.figure(figsize=(16,6))
librosa.display.specshow(chromagram,x_axis='time', y_axis='chroma', hop_length=512)
plt.show()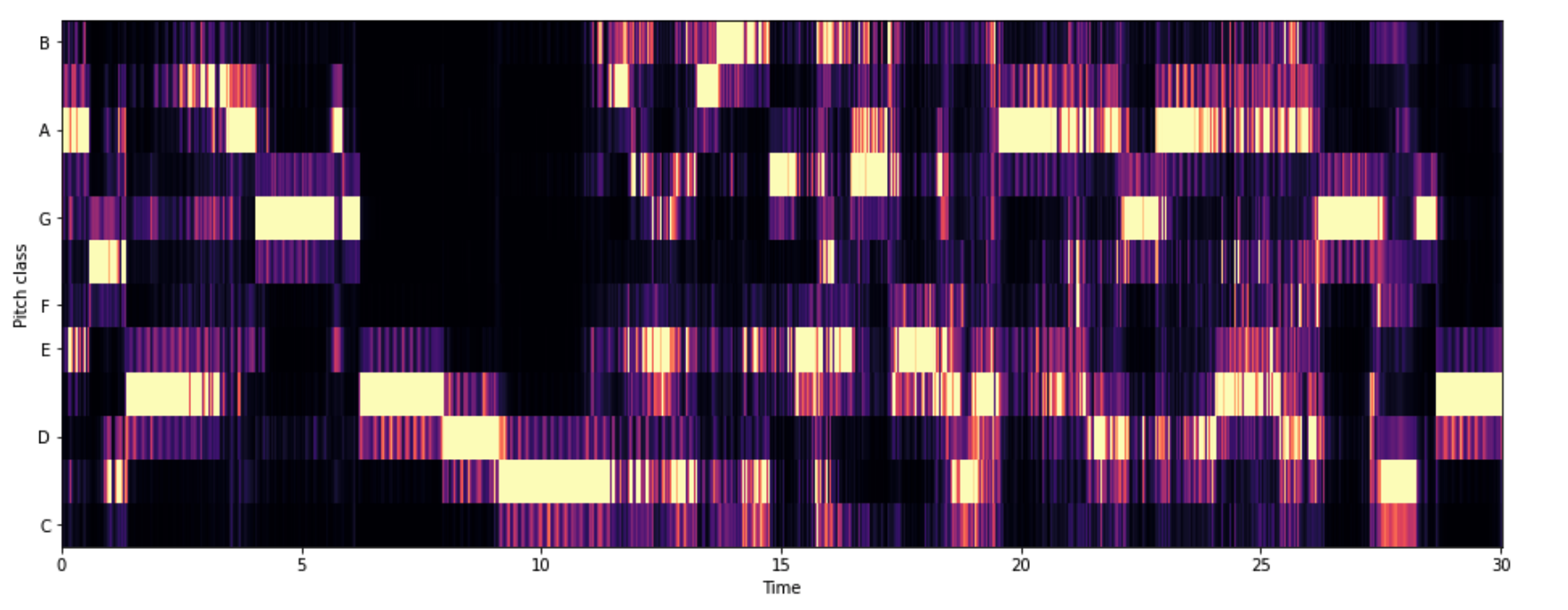
* 오디오 특징 추출하며 느낀점
- 이미지 처리와 다른 점은 , 이미지는 어떻게하면 더 효율적으로 특징을 추출할지를 고민한다면,
오디오는 최대한 많은 특징들을 추출해서 모델에 때려넣으면 알아서 잘 분류하겠지? 라는 느낌입니다. (주관)
- 그래서 그런지 시계열 처리보다는 특징을 추출해내는 것에 더 가깝게 느껴집니다.
4. 음악장르 분류 알고리즘
간단하게 위에서 살펴본 특징들을 학습시켜서 음악장르 분류 알고리즘을 만들어보겠습니다.
데이터는 kaggle 에서 이미 csv로 정리된 걸 가져와서 비교적 전처리는 쉬웠습니다.
4-1. 데이터 로드
import pandas as pd
df = pd.read_csv('Data/features_3_sec.csv')
df.head()
4-2. 전처리
X값에서 필요없는 열 삭제하고 Y값을 분리했다.
그리고 sklearn 에서 minmaxscaler 사용하여 값 0~1사이로 조정
X = df.drop(columns=['filename','length','label'])
y = df['label'] #장르명
scaler = sklearn.preprocessing.MinMaxScaler()
np_scaled = scaler.fit_transform(X)
X = pd.DataFrame(np_scaled, columns=X.columns)
X.head()
4-3. 데이터셋 분할
from sklearn.model_selection import train_test_split
X_train , X_test , y_train, y_test = train_test_split(X,y , test_size=0.2, random_state=2021)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
4-4. 학습 및 검증
from xgboost import XGBClassifier #xgboost 모델이 좋다길래 ..!!
from sklearn.metrics import accuracy_score
xgb = XGBClassifier(n_estimators=1000, learning_rate=0.05) #1000개의 가지? epoch? , 0.05 학습률
xgb.fit(X_train, y_train) #학습
y_preds = xgb.predict(X_test) #검증
print('Accuracy: %.2f' % accuracy_score(y_test,y_preds))
정확도는 0.88 나왔다. 가볍게 사용해봤을 때 나쁘지 않은 것 같습니다! xgboost 모델은 처음 써봤는데 뭔가 간소한 느낌? ...
4-5. Confusion Matrix(혼동 행렬)
: 지도학습으로 훈련된 알고리즘의 성능을 시각화 해주는 행렬
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm = confusion_matrix(y_test,y_preds)
plt.figure(figsize=(16,9))
sns.heatmap(
cm,
annot=True,
xticklabels=["blues","classical","country","disco","hiphop","jazz","metal","pop","reggae","rock"],
yticklabels=["blues","classical","country","disco","hiphop","jazz","metal","pop","reggae","rock"]
)
plt.show()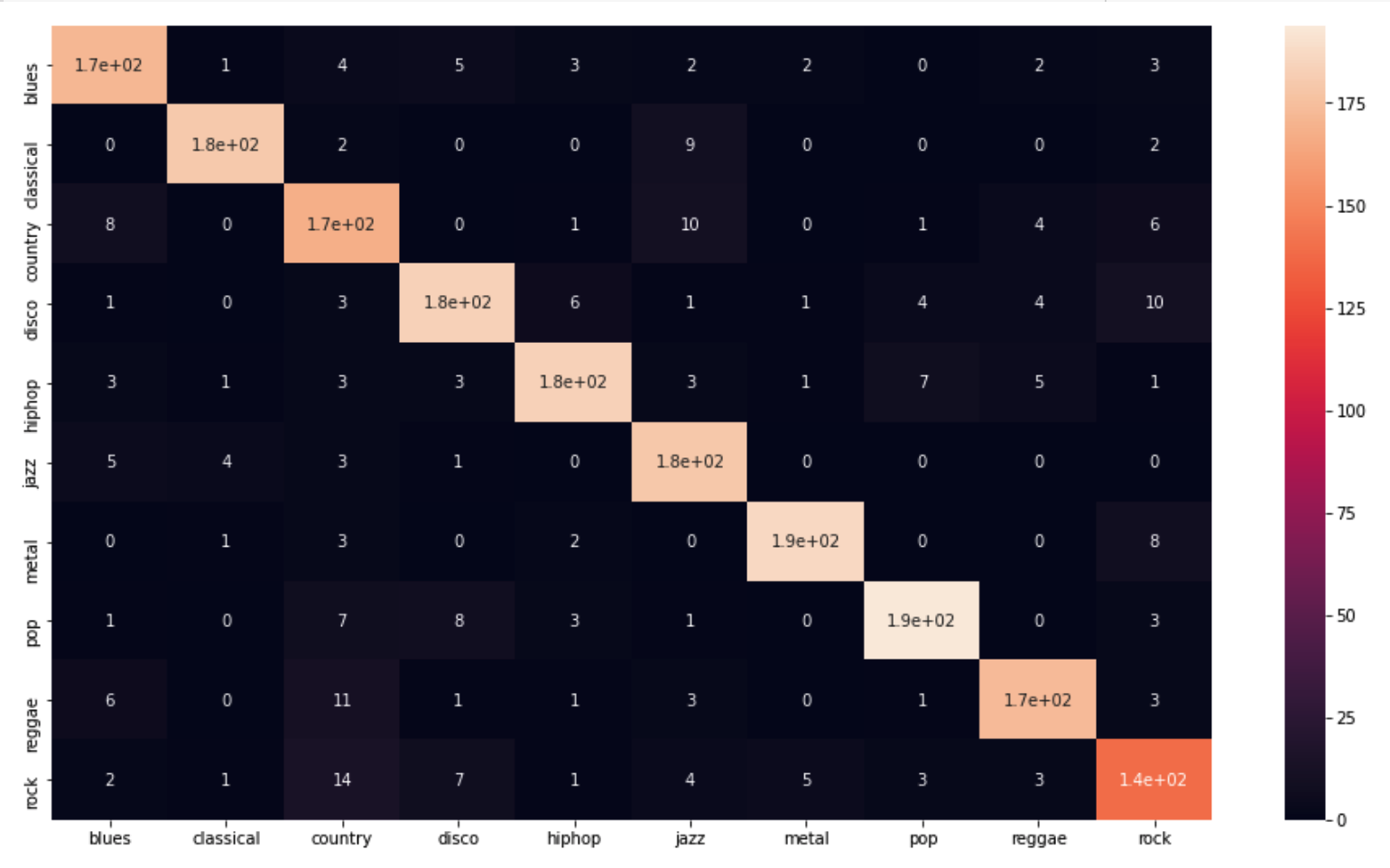
대체적으로 잘 맞추는 것을 볼 수 있습니다. 제일 못만춘 게 락을 컨트리음악으로 분류한 케이스이며 ,
아마 요즘같이 음악의 장르를 파괴하는 30호 가수같은 분들덕에 지금 멜론 차트에 있는 걸로하면 더 못맞추지 않을까 싶네요.
(장르가 30호!!)
마지막으로 어떤 특징이 분류에 가장 중요했는지 확인해봤는데, 음.. 대체로 비슷했고 perceptr_var 가 그나마 0.08로 가장 높았습니다.
for feature, importance in zip(X_test.columns, xgb.feature_importances_):
print('%s: %.2f' % (feature, importance)) #어떤 특징이 중요했는지 보여줌
5. 간단한 노래 추천 시스템
규칙은 위에서 추출한 특징들을 비교해서 유사도가 높은 상위 몇가지 노래를 추천해주는 형식입니다.
이때 유사도 비교는 벡터 유사도를 썼고, 노래는 상위 5개를 추천하는 걸로 했습니다.
5-1. 데이터 로드
df_30 = pd.read_csv('Data/features_30_sec.csv', index_col='filename')
labels = df_30[['label']]
df_30 = df_30.drop(columns=['length','label'])
df_30_scaled = sklearn.preprocessing.scale(df_30) #평균 0 , 표준편차 1
df_30 = pd.DataFrame(df_30_scaled, columns=df_30.columns)
df_30.head()
5-2. 유사도 설정
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity(df_30) #벡터의 유사도 , 즉 벡터간의 각도를 통해 추정 cos0 =1 이므로 1에 가까울 수록 유사 / cos180 = -1 이므로 -1에 가까울 수록 다르다.
sim_df = pd.DataFrame(similarity, index=labels.index, columns=labels.index)
sim_df.head()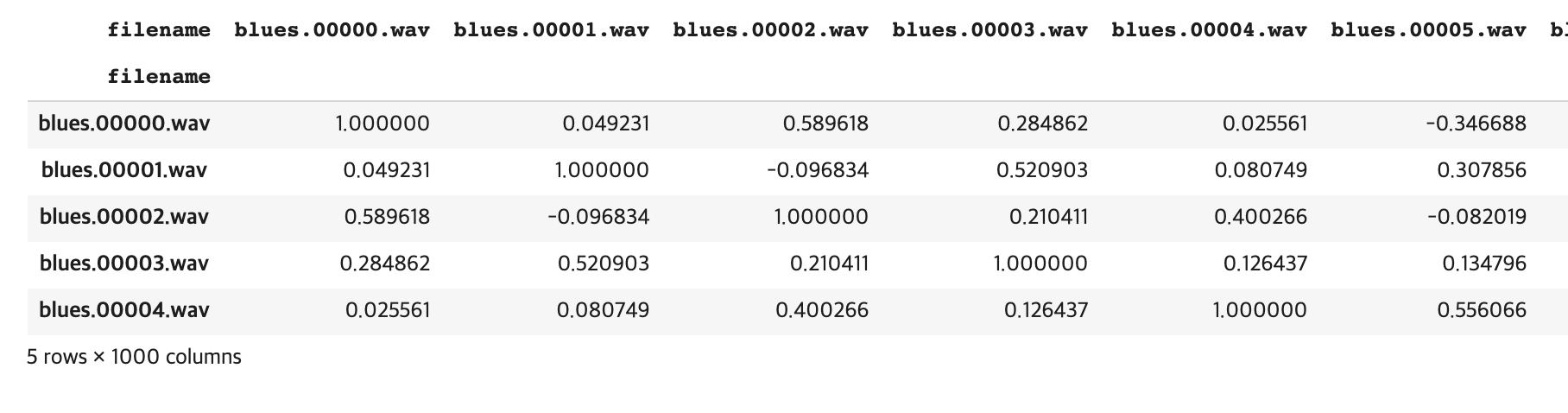
5-3. 함수화
def find_similar_songs(name, n=5):
series = sim_df[name].sort_values(ascending=False)
series = series.drop(name)
return series.head(n).to_frame()
find_similar_songs('rock.00000.wav')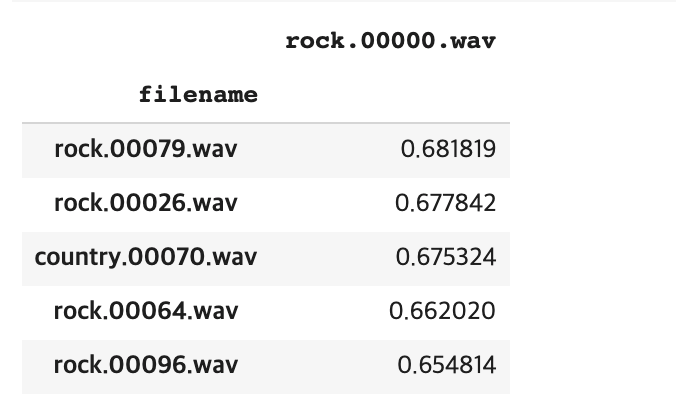
내가 지정한 음악을 넣었을 때, 그와 비슷한 음악 상위 5개를 여주는 것을 알 수 있다. rock 0번을 넣어서 한개뺴고는 rock음악을 추천해주는 것을 알 수 있다.
이번엔 처음으로 음성데이터에서 특성 추출을 해보고, csv 로 정리된 파일로 노래 분류 & 노래 추천 알고리즘을 짜봤다.
이것도 3월 31일에 해보고 2주나 미루다 정리했는데 정리하다보니 멜론에서 쇼미 음악들로 해서 한번 분류해봐도 재밌겠다 싶었다!
(예를 들어,프로듀서별로 나눠서 정말 성향이 비슷한지! / 시즌별 곡들의 성향 유사도 등)
https://link.coupang.com/a/NS8jv
Apple 2022 아이패드 에어 5세대
COUPANG
www.coupang.com
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
<참고자료>
www.youtube.com/watch?v=IE6lue0qusQ&list=PL-xmlFOn6TULrmwkXjRCDAas0ixd_NtyK&index=4
-기술 블로그 : https://tech.kakaoenterprise.com//66
AI에게 어떻게 음성을 가르칠까?
시작하며 인간은 귀로 듣고, 입으로 말하여 타인과 의사소통합니다. 나와 대화할 수 있는 존재를 창조하고 싶다는 바람은 많은 사람들이 오래전부터 상상하고, 소설로 쓰고, 연구해 왔습니다.
tech.kakaoenterprise.com
-깃허브 : github.com/jonhyuk0922/02.Music-Genre-Classification-Recommendation
jonhyuk0922/02.Music-Genre-Classification-Recommendation
Contribute to jonhyuk0922/02.Music-Genre-Classification-Recommendation development by creating an account on GitHub.
github.com
'머신러닝 & 딥러닝 공부 > 호기심 기록' 카테고리의 다른 글
| [딥러닝] 에폭(epoch) & 배치 사이즈(batch size) & 반복(iteration) 개념 정리 (0) | 2021.04.28 |
|---|---|
| [딥러닝] 왜 CNN의 Input_shape 은 4D일까? (1) | 2021.04.23 |
| [BeautyGAN] 화장해주는 인공지능 구현 (4) | 2021.03.31 |
| 나를 위한 딥러닝 용어정리 (0) | 2021.01.19 |
| 나를 위한 머신러닝 용어정리 (0) | 2021.01.19 |



