
[논문리뷰] Decoupled Side Information Fusion for Sequential Recommendation 논문 리뷰

안녕하세요~!
28년차 진로탐색꾼🧳 조녁입니다.
오랜만에 글을 쓰게됐네요!
오늘 리뷰할 논문은 업스테이지 & 홍콩과기대에서 발표한 "Decoupled Side Information Fusion for Sequential Recommendation"입니다.
기존의 방법론과 달리 SR을 수행할때 Side information을 통합한채로 어텐션에 집어넣는 것이 아니라, 어텐션을 진행한 후 통합하는 형태의 DIF-SR 방법론을 제시하고 있습니다.
논문선정 이유
회사에서 추천솔루션 고도화 업무를 하다가 리서치를 통해 업스테이지에서 AI Pack이라는 솔루션을 내보인다는 것을 보고 해당 논문을 보게됐다. 공개된 AI Pack은 Recbole 기반에다가 DIF-SR 아키텍처를 추가한 오픈소스로 DIF-SR 아키텍처에 대한 이해를 돕고자 논문을 선정하게되었다.
0. Abstract
- 추가 정보(side information)를 잘 활용해서 SR(sequential recommendation) 성능 높이는게 목적이다.
- 기존 SOTA는 어텐션 전에 추가 정보(side information)랑 아이템 임베딩을 통합해주는 방법을 탐색한다. 그러나, 우리가 봤을때 이른 통합은 rank bottlenect 으로 인해 어텐션 메트릭의 표현을 제한하고, 그레디언트 유연성을 구속한다. (아무튼 안좋다)
- 위 문제점 해결하고자 DIF-SR이 나옴.
- 추가 정보와 아이템 임베딩에 대한 어텐션 계산을 분리시킨다. (아래 그림들 보면 이해가 더 잘된다.)
- 어텐션 랭크 올리고 그레디언트 전파 유연하게해서 추가 정보 통합(Side information fusion)의 수용성을 늘렸다.
- 4개의 벤치마크로 실험을 많이 진행했는데 기존 SR SOTA보다 높은 걸 확인했다.
1. Introduction
- SR은 과거 유저행동 기반으로 다음 아이템을 추천하는게 목표임 , 온라인서비스에 적용가능하다보니, 요즘 핫한 연구임
- 딥러닝 베이스 모델[8,17,31] , 어텐션 베이스[11,25,28] , side information fusion[16,33,34,37]
- side info는 item id뿐 아니라 다른 속성 및 평점데이터를 사용함.
- 직관적으로 높은 관계있는 정보가 추천에 주요하다. 그러나 주변 정보를 어떻게 잘 활용하는 지도 open issue로 남아있다.
- 여러 단계에서 side info를 어떻게 효과적으로 적용시킬지 다들 노력중임. 특히 FDSA
- 아이템 셀프 어텐션과 주변정보를 어떻게 독립적으로 사전학습에 사용할 지 고민중.
- 최신논문은 side info를 어텐션하기 전에 아이템 representation으로 임베딩
- ICAI-SR[33]은 attribute-to-item 레이어로 어텐션 전에 side info를 시퀀셜 모델 학습을 위한 속성을 분리하는데 쓰인다.
- NOVA[16] 은 두개(side info & item embed)를 어텐션 레이어에 피딩한다. 여기서 item embed는 key, query 계산에만 쓰이고 value는 non-invasive하다.
- ealry-integration의 단점
- 어텐션 레이어 전에 임베딩 통합하면 렝크 보틀넥 생김
- 왜냐면 사영하면 쿼리키의 내적이 작아지기 때문이다. (최대값이 1이므로) <4.2.4에서 다룸>
- 관련없는 여러개의 소스를 섞어서 임베딩하다보니 임베딩 스페이스에서 random disturbance에 이르게 한다. 비슷한 결점인 포지션 인코딩은 [5,12]에서 다룸 , decoupled positional encoding은 [2,5]
- 통합된 임베딩이 어텐션 블록 전체에서 나눠질수없기 떄문이다.
- 널리사용되는 fusion방식은 학습을 위해 모든 임베딩이 같은 그레디언트를 공유하므로 모델이 side info encoding의 아이템 임베딩 측면 상대적 중요도를 학습하기에 제한이 있다.
- 어텐션 레이어 전에 임베딩 통합하면 렝크 보틀넥 생김
- 위 단점을 극복하기 위해 DIF-SR등장!
- we move the fusion process from the input to the attention layer
- 어텐션 레이어에 쓰이는 인풋과 속성의 쿼리 키를 따로 구해서 나중에 어텐션 메트릭을 fusion func로 합친다. 이렇게 rank 병목을 해결한다.
- 우리 솔루션은 capacity만 높여주는게 아니라, 속성이 섞여서 발생하는 불필요한 랜덤성도 피한다. 또한 다른 시나리오의 side info도 잘 학습함.
- 그 결과 기존 솔루션보다 더 좋다. 아마존의 Beauty Sports Toys Yelp 데이터에서 모두 효과적이다. 더욱이 기존 어텐션 기반 SR모델에 적용하기도 쉽다.
- 우리의 기여를 요약하면
- DIF-SR , 어텐션 capacity증대를 통해 효과적으로 사이드 정보를 시퀀스 추천에 사용하였으며, 사이드 정보의 상대적 중요도를 유연하게 학습하는 프레임워크를 선보였다.
- 기존의 어텐션 베이스 추천시스템에 쉽게 붙여 사용할 수 있는 novel-DIF 어텐션 메카니즘과 AAP-based training scheme을 제시했다.
- 이론 및 실험적으로 제안한 방법의 효과를 검증했다. 실제 데이터셋 여러개에 SOTA를 달성했으며, 우리 방법을 잘 설명해줬다.
2. Related work
2.1 Sequential Recommendation(SR)
- 키워드 : SAS-Rec , BERT4Rec
- 과거 seq interaction data기반으로 선호도 캐치하고 다음 아이템 예측하는게 목표다.
- 이전 SR은 복잡한 시퀀스는 다루기힘든, 마코브 체인 추정과 MF에 기반했었다.
- BERT4Rec와 같은 어텐션 기반모델은 예전엔 롱텀디펜던시를 풀었고, 최근엔 개인화[28],아이템 유사도[15], 일관성[7],다양한 이익[5], 정보전달[29],수도 증강[18], 모티브[3] 등에 포커싱되서 사용되고있다.
- 우린 나아가서 다양한 side info를 잘 녹여서 SR 기능향상에 도움을 주었다.
2.2 Side Information Fusion for Sequential Recommendation
- 키워드 : ICAL-SR[33] , p-RNN[9] , NOVA[16]
- 지금 추천에서 중요한 연구주제 중 하나다.
- FDSA[34]에서는 side info 와 item 을 다른 어텐션으로 인코딩한다. 그러고 final stage까지 합쳐지지않는다.
- S3-Rec[37]는 프리트레인할때도 side info를 쓴다.
- 그러나 위의 것들이 그다지 효율적으로 side info를 사용하지 못함
- 최근 연구들은 final representation에서 side info를 고려하게 하기 위해 어텐션 전에 side info 와 item embed를 합쳐줬었다.
3. Problem Formulation
- 연구 주제 : side info integreted sequential recommendation
- side info는 예측을 위해 사용되는 유저, 아이템, 행동의 속성이 될 수도 있다.
- 아이템 관련 정보 - brand, category
- 행동 관련 정보 - position, rating
- seq recom을 위해 side info를 representation해야함.
4. Methodology
- DIF-SR이 효과적이고 유연하게 side info를 다음 아이템 예측에 사용되도록 합치는걸 보여줄 것이다.
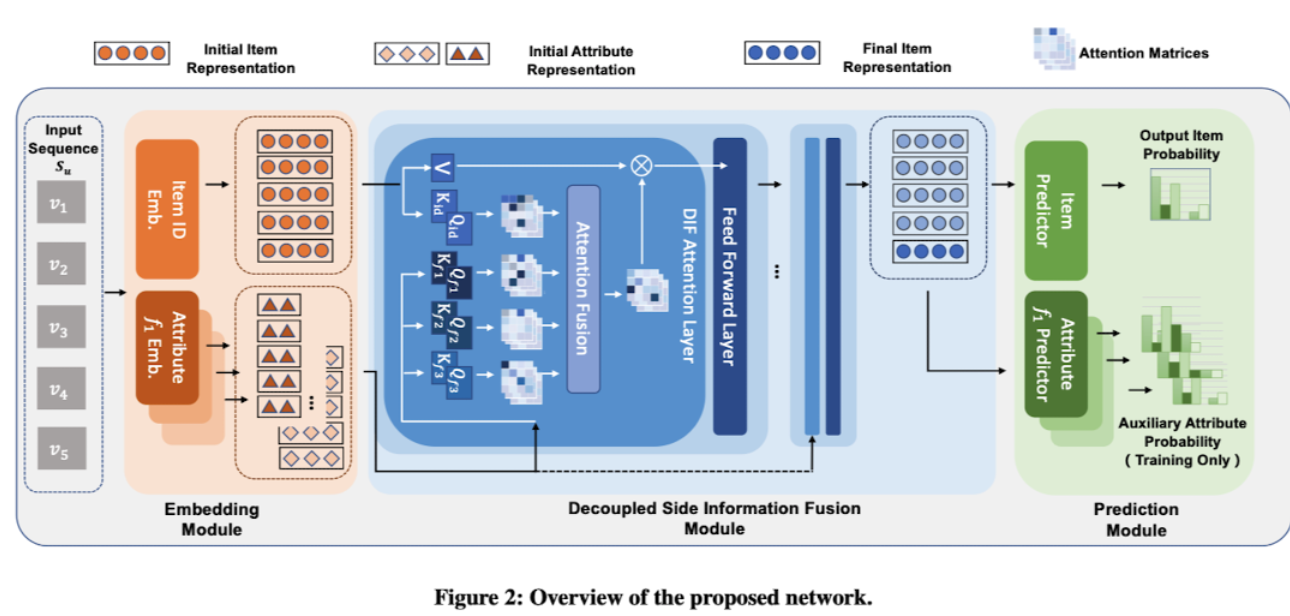
4.1 Embedding Module
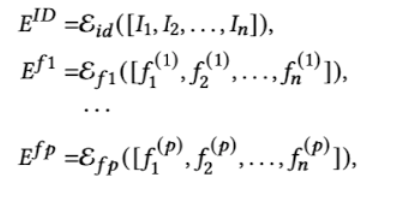
- input seq $S_u$ 는 각각 임베딩 레이어에 인풋으로 들어가서 Item ID , f1(속성) 에 대해 다 각각 임베딩해준다.
- (5.4.3 참고) 각 속성마다 유연하게 임베딩 차원을 조절할 수 있다.
- 속성에 대해 아이템보다 훨씬 작은 차원 적용가능해서 성능 손상없이 네트워크의 효율성 높인다.
4.2 Decoupled Side Information Fusion Module
- 4.2.1에서 전체구조를 보고 4.2.2에서 이전의 셀프어텐션을 살펴보고, DIF 어텐션을 4.2.3에서 살펴본다. 그리고 DIF의 어텐션 메트릭 랭크와 그레디언트 유연성에 대해 4.2.4에서 설명한다
4.2.1 Layer Structure
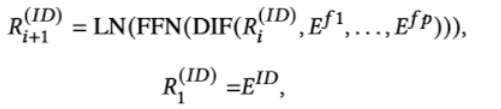
- 여러개의 어텐션 레이어과 feed forward layer의 조합으로 구성되어있다.
- 멀티헤드 어텐션을 DIF 에턴션으로 바꾼거 외의 블럭구조는 SASRec[11]과 동일하다.
- 인풋으로는 사이드인포 임베딩과 아이템 representation 두가지 타입이 있으며, 아웃풋은 item representation으로 나온다.
- 사이드임포 임베딩은 계산 절약과 오버피팅 방지를 위해 레이어마다 업데이트 되지는 않는다.
4.2.2 Prior Attention Solutions
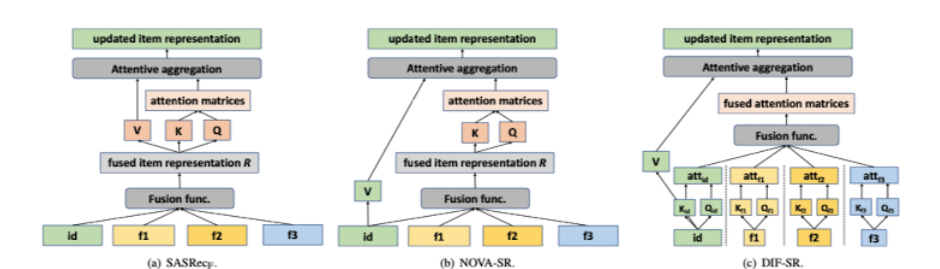
- SASRec_F : 우리가 아는 셀프-어텐션 방식. (input length n , hidden size d)
- R : 임베딩값 , W: 웨이트 , 𝜎 : 소프트맥스
- side info가 item representation에 영향을 주지만, Value(Item embedding)의 정보손실(침해)의 단점이 있다.
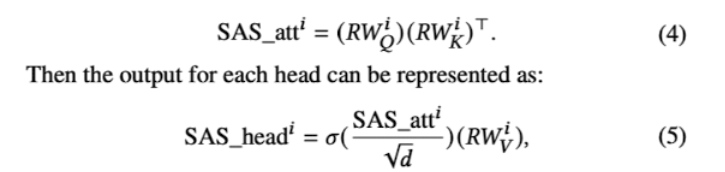
- NOVA : 위의 문제점(invasion problem) 해결위헤 Value를 pure하게 id embedding해서 따로 뺴온다.
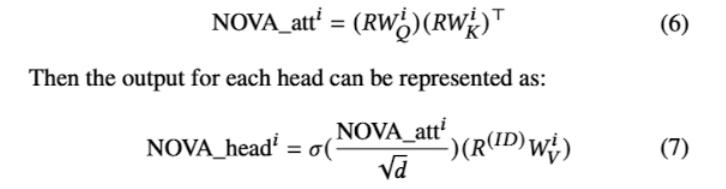
- DIF-SR (4.2.3) : value의 invasion problem은 해결됐지만, key와 value값 계산에 있어 어텐션 랭크나 그레디언트 유연성 문제는 여전히 있다. (이론은 4.2.4)
- decoupled attention을 통해 rank bottleneck을 해결해서 표현력이 증진되었다.
- 각 속성에 대해서 따로 계산 하다보니, gradient의 inflexible한 것도 피함. (만약 합쳐서 어텐션 취하면 모두 동일한 d에서 계산되어야한다)
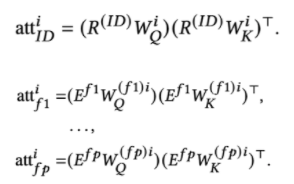
- F = fusion function , including addition, concatenation, and gating, and gets the output for each head
- 마지막 아웃풋은 concat해서 ffd에 들어감
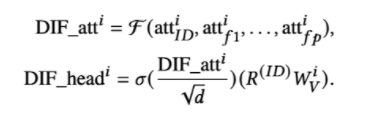
4.2.4 Theoretical Analysis
- DIF에서 제안된 것과 이전의 positional embedding에 대한 분석을 이론적으로 할거고 증명은 A proof에 있음.
- 이론은 굿노트에서 정리함. 요약하면,
- $rank(att)<= d_h , rank(DIF-att) = d_h +$ 1~p 각속성의 hidden dim의 합 > $d_h$
- flexible 한 건, 각각 임베딩의 차원이 달라지므로!!
4.3 Prediction Module with AAP
- side info 와 Item embed 사이 AAP 사용할 것 권장
- 기존과 차이점
- 분리된 속성 임베딩 사용
- 프리트레인에만 속성 사용
- 우리는 복수의 예측기로 side info를 최종 item represent에 사용해서 한번에 예측하기 (??) (5.4.1)
- Early integration 베이스 모델보다 성능 향상 뛰어남.
- 속성 j 예측에 대한 수식
- b 는 학습가능한 bias , 활성화함수는 시그모이드
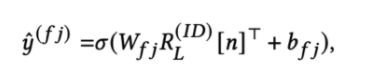
5. Experiments
RQ1: Does DIF-SR outperform the current state-of-the-art basic SR methods and side information integrated SR methods?
RQ2:Can the proposed DIF and AAP be readily incorporated into the state-of-the-art self-attention based models and boost the performance?
RQ3: What is the effect of different components and hyper- parameters in the DIF-SR framework?
6. Conculusion
- moving side information from input to the attention layer
- 즉, 원래 input 단에서 side information 을 통합(fusion)했던게 기존의 아키텍처였다면, side information을 통합(fusion)하지 않고 어텐션 레이어의 입력값으로 옮긴게 DIF-SR의 특징이며, 이로 인해 4가지 벤치마크에서 SOTA를 달성한게 기여하는 포인트다.