[논문리뷰] Deep Neural Networks for YouTube Recommendations 논문 리뷰

안녕하세요~!
28년차 진로탐색꾼 조녁입니다!!
오늘은 구글의 유튜브(YouTube)추천 논문 3편 중 2번째 논문인 Deep Neural Networks for YouTube Recommendations를 리뷰해보려합니다.
원논문의 순서를 따라 리뷰했으며, 내용에 있어 어떠한 의견도 늘 환영입니다!!
0. 논문 선정 이유
시작하기 전에, 6년전 논문임에도 원논문을 선정한 이유에 대해서 얘기해보고 싶습니다.
1. 유튜브는 제가 겪어본 가장 강력한 추천 시스템이기에 선정했습니다. 지금도 매달 만원이상의 돈이 제 통장에서 빠져나가고 있습니다 ㅎ.. (유튜브 프리미엄 못잃어..)
2. 연구가 아닌, 실제 서비스를 기반으로 작성된 논문이라서 선정하게되었습니다.
이전에 주로 사용되던 MovieLens , Netflix, Music Recsys 등 데이터셋은 몇십만인데 비해, 실제 서비스에선 몇천만 이상의 데이터가 발생할 수 있습니다. 이에 따라 연구에서 SOTA를 찍은 모델들일지라도, 실제 서비스에선 차이가 발생할 수 있습니다. 원논문에선 모델 아키텍처뿐 아니라, 구글이 유튜브를 운영하며 경험적으로 얻은 Feature Selection Tip과 같은 내용또한 포함하고 있습니다.
1. 요약(Abstract)
- 유튜브(YouTube)는 대표적인 엄청 큰 개인화 서비스입니다. 이 논문에선 딥러닝을 통한 엄청난 성능 개선을 high-level에서 알려줄 것입니다. 모델은 두 가지 단계로 나눠지는데, 우선 Candidate Generation Model(후보생성 모델)과 이후의 구분된 Ranking Model(랭킹 모델)을 설명할 것입니다.
- 또한, 실제적으로 유저를 대상으로 대규모 추천시스템 구축 및 유지를 경험하며 생긴 교훈들도 같이 제공하고 있습니다.
2. 개요(Introduction) : 실제로 딥러닝을 통해 서비스의 성능을 개선함
- 실제 상황에서 겪게 되는 이슈들(Challenging from three major perspectives)
- Scale : 엄청난 양의 데이터와 제한된 컴퓨팅 파워로 인해, 고도로 전문화된 분산 학습 알고리즘과 효율적인 서빙 시스템이 필수
- Freshness : 새로운 컨텐츠의 빠른 적용이 필요하다. 따라서, 초당 몇 개가 업데이트되는 상황에서 반영할 수 있어야 함
- Noise : 낮은 meta data 퀄리티(sparse , many external factors) 및 Implicit Feedback(시청 이력) 위주 데이터가 주를 이룬다. 이러한 특정 특징에 강력한 알고리즘이 필요
- 위의 문제를 범용적으로 해결하기 위해 DL을 제시하고 있으며, 아래 2가지 레퍼런스(분산처리 & 의미분석)도 가볍게 살펴볼 수 있다.
- 구글이 사용하는 보편적인 대규모 분산 딥러닝 모델(2012, Large Scale Distributed Deep)
- 비지도 학습과 함께 대규모 학습이 가능해짐. 수십억 개의 파라미터 학습을 위해 수만 개의 CPU 사용, DistBelief라는 소프트웨어 개발함.
- Downpour SGD , Sandblaster L-BFGS 두 가지 알고리즘을 통해 학습 규모 & 속도 개선
- (sementic segmentation 의미분석) (2016, TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems)
[👇 더보기 클릭 시 사진 노출] sementic segmentation 예시
1. 1마리 강아지 잘 인식합니다.

2. 다수의 사람도 잘 인식합니다.

3. 그러나, 작게보이는 다수의 사람들은 배경으로 인식합니다.

4. 뒤에 작게 보이는 사람은 배경으로 인식하고, 앞에 크게 보이는 사람은 제대로 인식합니다.

5. 배경과 비슷한 색의 강아지를 배경으로 잘못인식합니다.

- 이후 Chap3에선 간단한 Overview를 제시하고, Chap4에선 후보생성모델(Candidate Generation Model)이 어떻게 학습되고 사용되는 지 자세히 다룹니다. 실험결과를 통해, 어떻게 딥러닝(DL)과 추가적인 다른 신호(additional heterogeneous signals)가 모델 성능에 도움이 됐는 지 보여줍니다. Chap5에선 랭킹모델(Ranking Model)이 전통 로지스틱 회귀를 어떻게 수정해서 기대 시청시간 예측모델을 학습시켰는지 보여줍니다.
3. 전반적인 모델 설명(System overview)

- 전체 비디오의 유저 히스토리를 보고 협업필터링을 통해 candidate generate(후보 선출)을 몇백 개 추려낸다. → 랭킹 모델의 후보군은 많지 않으므로 추가 피처들을 추가해서 랭킹모델을 돌린다. 결과적으로 우선순위 몇십 개의 영상이 나온다.
- 컨텐츠 기반 필터링 : 내가 액션을 취한 컨텐츠와 비슷한 컨텐츠 추천
- 협업 필터링 : 사용자의 구매이력, 평점 등 사용자 행동 기반하여 추천
- [👇 더보기 클릭 시 사진 노출] 예시

- Candidate Generation Model : High-precision 이 목표
- precision : 진짜라고 예측(Positive)한 것들 중 진짜(True)의 비율(암환자로 예측한 환자 중 실제 암환자 비율)
- recall : 실제로 positive한 애들 중 올바르게 예측한 비율(실제 암환자 중 암환자로 예측한 비율)
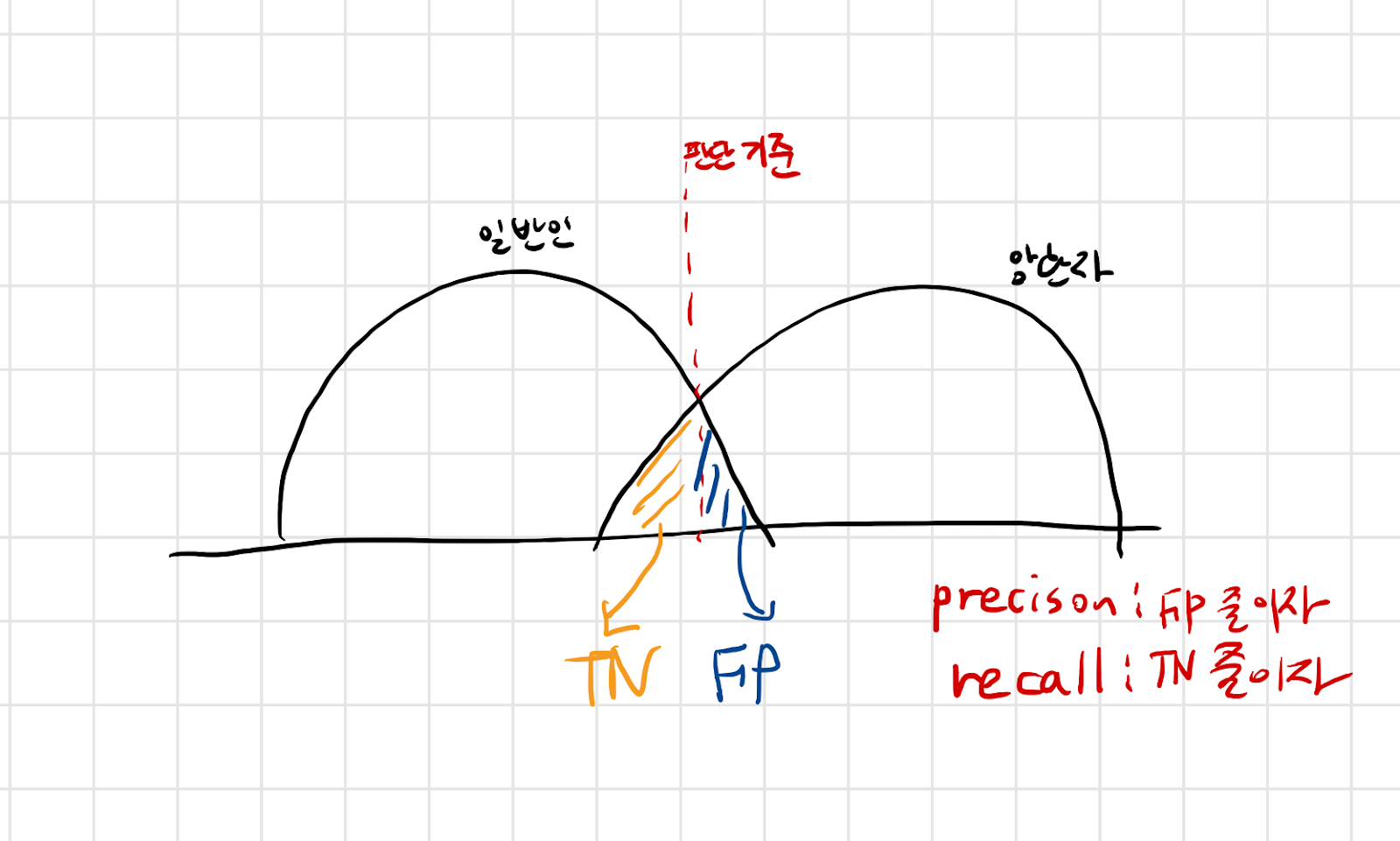
** 오타 : TN -> FN
- Ranking Model : 다양한 다른 소스들(피처들)을 포함하여 성능 개선시킴
4. 후보생성모델(Candidate Generation Model)
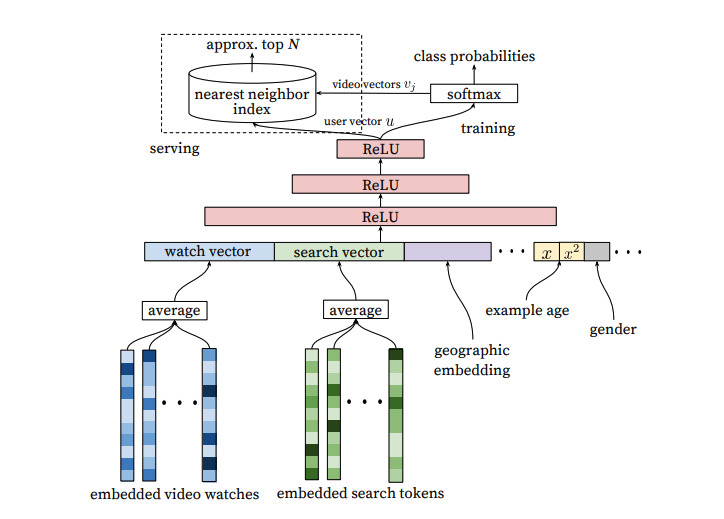
- 위 그림이 후보생성모델의 전체 아키텍처이며, 아래 6단계로 나눠서 리뷰해보도록하겠습니다.
- video watches & search tokens 를 각각 dense embedding
- 모델에 feeding하기 위한 input combiner
- Additional features
- DNN Layers(ReLU Stack)
- Softmax Prediction(with Negative Sampling)
- Serving (NNS Algorithm)
4.1. video watches & search tokens 를 각각 dense embedding

The task of the deep neural network is to learn user embeddings u as a function of the user’s history and context that are useful for discriminating among videos with a softmax classifier.
- Video Embedding과 Search Token Embedding은, 각각 유저 한 명의 시청 이력과 검색 이력이다.
- 높은 차원 임베딩(sparse)을 각 영상 별 단어(키워드)로 바꾸고 학습시킨다.
- 오차역전파(back propagation)을 통해 embedding하는 부분까지 학습한다.
(뇌피셜) 과연 video watches 를 어떻게 embedding하는걸까?
첫번째, 영상 썸네일(Image)을 의미분석한 키워드에 제목(Text)을 더한값으로 각 영상을 태깅해준다.
(레퍼런스 : 이미지 의미분석 코드)
두번째, 위의 값을 Input으로 Feedforward Network에 넣어주면 Dense Embedding 이 나온다.
4.2.모델에 feeding하기 위한 input combiner
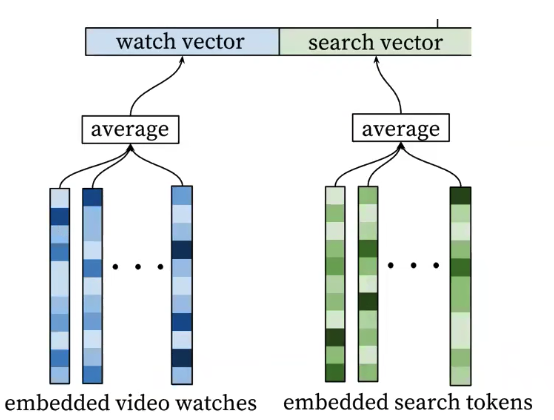
- 모델학습을 위해 고정된 사이즈의 Input으로 변환해준다.
- 다양한 방법(sum , concat, average)을 사용해봤는데 average가 성능이 제일 좋음
4.3. Additional features

- geographic embedding(지역, 기기 등)
- example age(영상의 나이)
- 모두 단순하게 concat해서 큰 Input을 만든다.
영상의 나이(example age)피처에 대해서 더 살펴보면,
베이스라인일때는 실제(Empirical Distribution)분포와 다르게 나오지만, 베이스라인에 영상의 나이(Example age) 피처를 추가하면 실제분포와 유사해지는 걸 확인할 수 있습니다.
- Freshness is very important
- 히스토리 데이터를 기반으로 학습을 시키면 오래된 아이템들이 더 추천을 많이 받는 현상
- "영상의 나이"를 추가 feature로 넣어보자!! (concat)

4.4. DNN Layers (ReLU Stack)
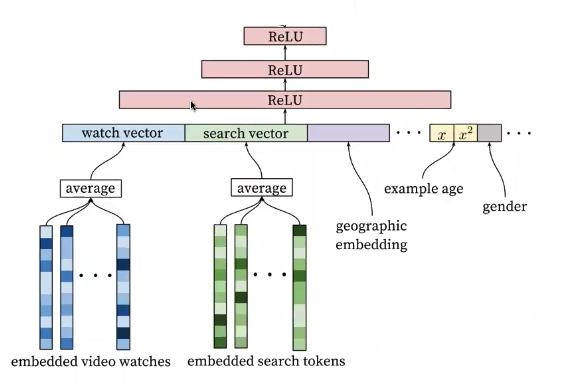
- Fully connected "Tower" : 점점 좁은 쪽으로 통과시킨다.
- Output으로 user embedding이 나온다. (user embedding은, 유저의 선호도 정보)
여기서 실험적으로,
Layer는 더 넓게 쌓는 것이 더 좋은 성능을 내는 걸 확인하실 수 있습니다.

4.5. Softmax Prediction (with Negative Sampling)

- user embedding에 softmax를 취해주면, video 별 가중치가 output으로 나온다.
- e.g) [0.4, 0.2, 0.1, 0.3]
- Negative Sampling : 수천개의 샘플만 뽑아서 샘플링 된것을 통해 학습을 시킨다. (100배 이상 시간 단축!!)
4.6. Serving (NNS Algorithm)
- 상위 N개의 비디오 : user vector u + 학습된 video vector v_j
- Dot-product space에서 가장 가까운 아이템을 찾음
- Nearest Neighbor 알고리즘간에 성능차이는 크지않으므로 결과를 빨리 내는게 중요
다만, 논문은 16년도까지의 nns 알고리즘 기준이었기에, 최근에는 아래 최신표 참고하여 비교해보시면 좋을 것 같습니다.

그 외 실제 환경을 고려한 요소들
- 모든 비디오 시청이력을 확인해야 bias가 없다. (외부 사이트 포함)
- 학습에 사용할 이용자별 영상 횟수를 fix해야 heavy user(영상 많이 본 유저) 에 치우치지 않는다.
- 새로운 검색 쿼리에 즉시 추천엔진을 반영하지 않는다. (한번 검색했을 뿐일 수도 있다)
- 비대칭적인 감상 패턴을 적용해서 학습 시킨다. (영상을 규칙적으로 보지않는다. 딥러닝 영상볼땐 그거 쭉 보다가, 게임 영상볼떈 그걸 쭉 본다.)

위 Figure 5와 같이 비대칭적인 감상 패턴을 적용해서 학습시키면, 미래정보 누설 및 불규칙 영상소비 패턴을 무시하게된다.
5. 랭킹모델(Ranking Model)

- 앞선 과정에서 생성한 후보군(높은 확률로 클릭할) 영상들을 모두 볼 수도 있지만, 특정 썸네일에 따라 안 누를 수도 있기때문에 랭킹모델을 통해 수십개로 줄여줍니다.
- Input으로 들어가는 영상의 갯수가 줄어들었기 때문에 추가적으로 유저 & 영상간 관계 파악하기 위해 피처들을 추가해줍니다.
- 아래 4가지 과정을 통해 랭킹모델(Ranking Model)을 리뷰해보겠습니다.
- 피처들을 각각 Embedding
- Ranking Model
- Task : Expected Watch Time
- 피처가 많으므로, Feature Engineering
1. 피처들을 각각 Embedding

- 후보 생성 모델과 달리, Input의 갯수가 많지 않으므로 많은 Feature들을 넣어준다.
- 후보 생성 모델과 같은 ID space , embedding 사용한다.
- 직전 시청이력은 average해서도 쓰고, 직접 원본 그대로도 쓴다.
- continuous features는 normalize해서 사용
2. Ranking Model
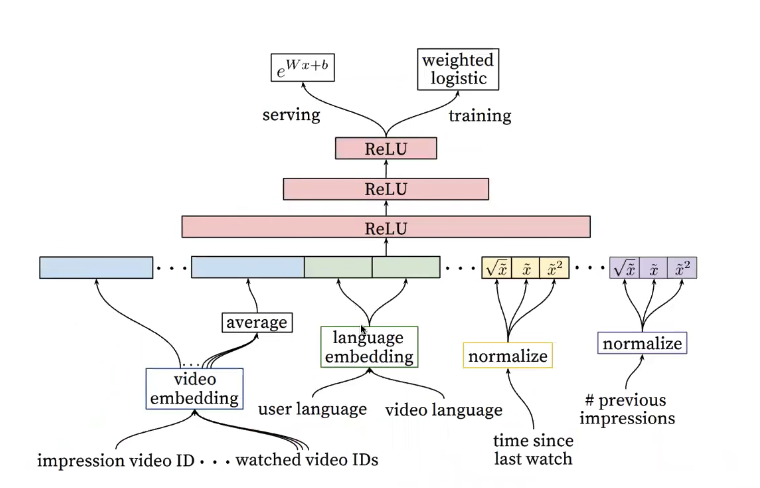
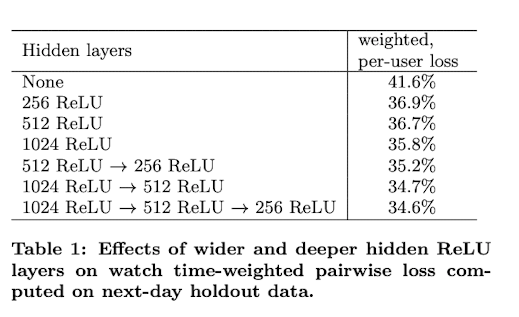
- 깊고 넓을 수록 성능이 잘 나온다. (아래 실험결과 표 참고)
3. Task : Expected Watch Time

- 후킹용 영상 클릭 데이터를 제외하기 위해, 추천된 영상을 얼마나 오래동안 볼지 예측하는 것을 목표로함
- 감상시간은 안봤으면 0, 봤으면 본 시간을 값으로 입력
- 감상 시간으로 가중치를 준다.(Weighted logistic regression) , CTR보다 효과적이다.
4. 피처가 많으므로 , Feature Engineering

- 각 feature들을 어느정도 가공해줘야 한다.
- 특히나 시간 연속성을 가진 데이터들은 summarizing이 필요
- 사용자 이용패턴, 추천했는데 보지않았던 영상 등도 활용
- 가장 좋은 feature는 비슷한 비디오에 대한 유저의 반응
6. 결론
1. 우리의 여러층의 DeepCF 모델은 기존의 방법(matrix factorization) [23] 보다 성능을 많이 향상 시켰다.
2. "영상의 나이"가 성능을 크게 개선 시켰다. 오프라인에서 precision을 , 온라인 A/B 테스트에서 시청시간 예측을 향상시켰다. (온라인 A/B 테스트가 중요하다)
3. 모든 것을 딥러닝으로 하기는 쉽지 않다. (파이프라인 구축, 임베딩 방법 등 중요)
딥러닝은 Category features와 Continuous features를 임베딩 및 quantile normalization를 각각 해줘야한다.
그럼에도 딥러닝을 쓰는 이유는, 수많은 피처들이 비선형성을 통해 효율적으로 표현되어 성능이 향상되기 때문이다.
4. positive data는 감상 시간에 가중치를 주고, negative data는 unity(통일성)에 가중치를 준 것도 개선점이 컸다. (CTR일때보다 시청시간예측에서 더 주요함)
참고자료
NBT 발표 : https://www.youtube.com/watch?v=V6zixdCIOqw&t=569s
recall , precision 개념 : https://j-i-y-u.tistory.com/37
추천시스템 전반 : https://lsjsj92.tistory.com/563
ANN 알고리즘 비교 : https://aaoossiinnaa.tistory.com/87
네거티브 샘플링 : https://wikidocs.net/69141